
There are various options on how to save hierarchical data in SQL Server. This article is an overview of them demonstrating their usage on a simple dataset of employees and their managers. I will extend this article when a new option will be available or if you will advise it in Comment.
[toc]
Preparing data
Let’s create some sample data first. Nothing complicated: simple list of employees and their managers like it’s common in the organization hierarchy. It has two parent nodes (AMY and LAURA) and up to five child levels. I kept it simple for demonstration purposes and each employee’s name is unique and every employee has only one manager. Most of the options will work for multiple parents (navigation) paths too but it may require some changes. I will post on the multiple-parent hierarchy later.
CREATE TABLE [#Source] ( [Employee_Id] INT NOT NULL PRIMARY KEY, [Name] NVARCHAR(100) NOT NULL, [Manager] NVARCHAR(100) NULL ) ;WITH [c] ( [Employee_Id], [Name], [Manager] ) AS ( SELECT 1, 'AMY', NULL UNION ALL SELECT 2, 'DANIEL', 'AMY' UNION ALL SELECT 3, 'EMILY', 'AMY' UNION ALL SELECT 4, 'HANNAH', 'AMY' UNION ALL SELECT 5, 'JACK', 'HANNAH' UNION ALL SELECT 6, 'JAMES', 'HANNAH' UNION ALL SELECT 7, 'JESSICA', 'JAMES' UNION ALL SELECT 8, 'JOSHUA', 'JAMES' UNION ALL SELECT 9, 'LAURA', NULL UNION ALL SELECT 10, 'LUKE', 'LAURA' UNION ALL SELECT 11, 'MATTHEW', 'LAURA' UNION ALL SELECT 12, 'OLIVIA', 'MATTHEW' UNION ALL SELECT 13, 'REBECCA', 'MATTHEW' UNION ALL SELECT 14, 'RYAN', 'REBECCA' UNION ALL SELECT 15, 'SOPHIE', 'RYAN' UNION ALL SELECT 16, 'THOMAS', 'SOPHIE' ) INSERT INTO [#Source] ( [Employee_Id], [Name], [Manager] ) SELECT [c].[Employee_Id], [c].[Name], [c].[Manager] FROM [c] SELECT * FROM [#Source] GO
The script above will create [#Source] temporary table with the following data:
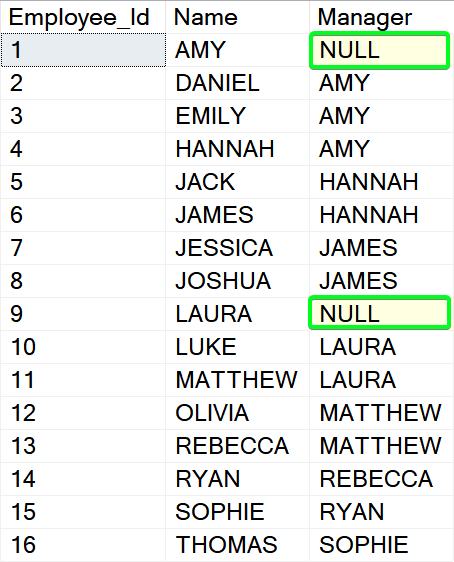
Please note that AMY and LAURA have Manager fields empty. They are our super bosses, two top-level nodes where the hierarchy path tree is starting.
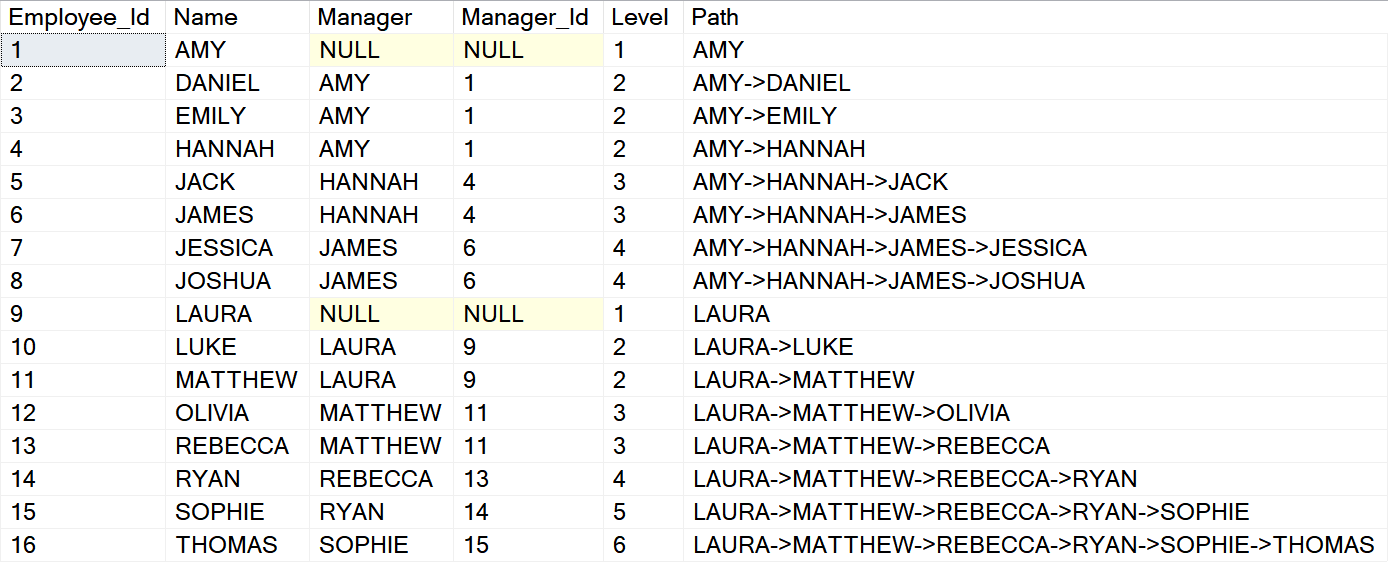
We will a little bit transform this basic dataset user recursive CTE and save it as an optimized dataset into the [#Data] table.
CREATE TABLE [#Data] ( [Employee_Id] INT NOT NULL PRIMARY KEY, [Name] NVARCHAR(100) NOT NULL, [Manager] NVARCHAR(100) NULL, [Manager_Id] INT NULL, [Level] INT NOT NULL, [Path] NVARCHAR(MAX) NOT NULL ) ;WITH [c] AS ( SELECT [Employee_Id], [Name], [Manager], CAST(NULL AS INT) [Manager_Id], 1 [Level], CAST([Name] AS NVARCHAR(MAX)) AS [Path] FROM [#Source] WHERE [Manager] IS NULL UNION ALL SELECT [d].[Employee_Id], [d].[Name], [d].[Manager], [c].[Employee_Id], [c].[Level] + 1, [c].[Path] + '->' + [d].[Name] FROM [#Source] [d] INNER JOIN [c] ON [c].[Name] = [d].[Manager] ) INSERT INTO [#Data] ( [Employee_Id], [Name], [Manager], [Manager_Id], [Level], [Path] ) SELECT [Employee_Id], [Name], [Manager], [Manager_Id], [Level], [Path] FROM [c] SELECT * FROM [#Data] GO
We can see the source hierarchy presented visually now and we will save some data processing later.
Adjacency list (Parent/Child)
This is probably the most used option to persist hierarchical data in SQL Server (and other RDBMS). It persists the reference to the parent node in every child node.
CREATE TABLE [dbo].[Employees_Adjacency]
(
[Employee_Id] INT NOT NULL PRIMARY KEY,
[Name] NVARCHAR(100) NOT NULL,
[Parent_Employee_Id] INT NULL,
CONSTRAINT [FK_Employees_Adjacency]
FOREIGN KEY ( [Parent_Employee_Id]) REFERENCES [dbo].[Employees_Adjacency] ([Employee_Id])
)
GO
INSERT INTO [dbo].[Employees_Adjacency]
( [Employee_Id], [Name], [Parent_Employee_Id] )
SELECT [Employee_Id], [Name], [Manager_Id]
FROM [#Data]
GO
SELECT * FROM [dbo].[Employees_Adjacency]
GO
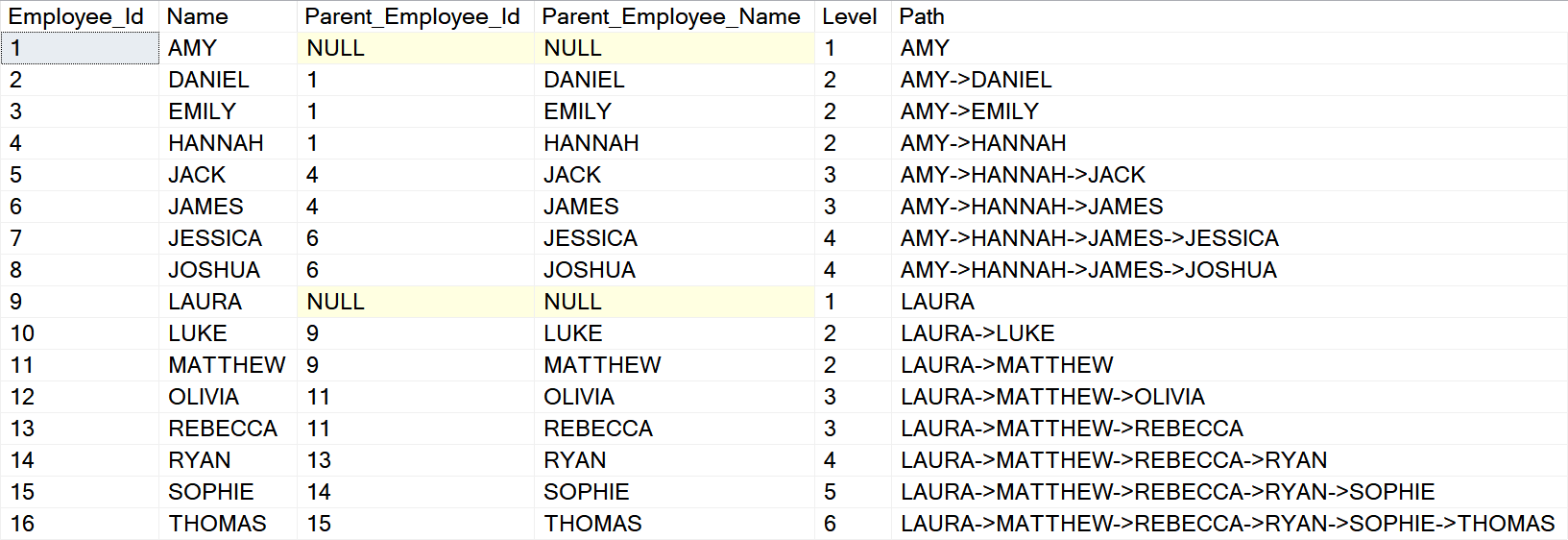
We have created [dbo].[Employees_Adjacency] with the self-referencing [Parent_Employee_Id] column (note the highlighted FK constraint) and populated it with data from [#Data] table:
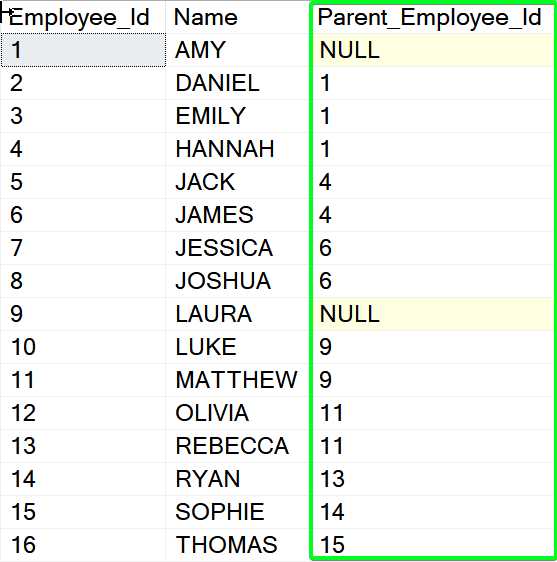
It’s very similar to the original [#Source] except that Manager of every employee is expressed in the [Parent_Employee_Id] as a reference to the [Employee_Id] unique employee Id (Primary Key).
We can revert the process now and check if the parent-child hierarchy is correct using recursive CTE:
;WITH [c] AS ( SELECT [Employee_Id], [Name], [Parent_Employee_Id], CAST(NULL AS NVARCHAR(100)) [Parent_Employee_Name], 1 [Level], CAST([Name] AS NVARCHAR(MAX)) AS [Path] FROM [dbo].[Employees_Adjacency] WHERE [Parent_Employee_Id] IS NULL UNION ALL SELECT [d].[Employee_Id], [d].[Name], [d].[Parent_Employee_Id], [d].[Name], [c].[Level] + 1, [c].[Path] + '->' + [d].[Name] FROM [dbo].[Employees_Adjacency] [d] INNER JOIN [c] ON [c].[Employee_Id] = [d].[Parent_Employee_Id] ) SELECT [c].[Employee_Id], [c].[Name], [c].[Parent_Employee_Id], [c].[Parent_Employee_Name], [c].[Level], [c].[Path] FROM [c]
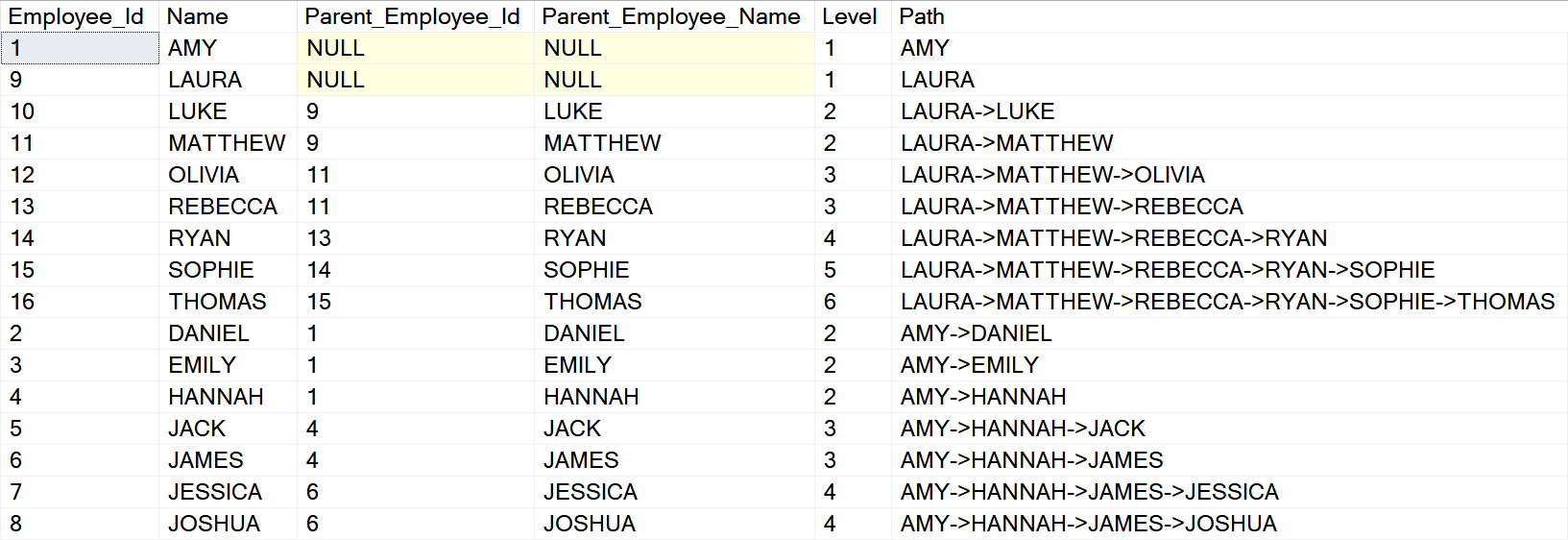
It perfectly matches our original source.
Closure table
This is similar to an adjacency list. The only main difference is that the parent-child relationship is stored separately from the data itself.
This can be done in two ways: We will simply move the hierarchy to a different table as it is or we will transform it a little bit and switch the key and parent-key column.
Simple movement of the hierarchy to a dedicated table
CREATE TABLE [dbo].[Employees] ( [Employee_Id] INT NOT NULL PRIMARY KEY, [Name] NVARCHAR(100) NOT NULL ) GO INSERT INTO [dbo].[Employees] ( [Employee_Id], [Name] ) SELECT [Employee_Id], [Name] FROM [#Data] GO SELECT * FROM [dbo].[Employees] GO
We have created [dbo].[Employees] table and filled just employee ids and names. There is nothing about the hierarchy.

We need to create a dedicated table [dbo].[Employees_Hierarchy_1] to save all the hierarchical relations between individual employees now. Please note that the [Employee_Id] is the only participant in the unique primary key constraint.
CREATE TABLE [dbo].[Employees_Hierarchy_1] ( [Employee_Id] INT NOT NULL PRIMARY KEY, [Parent_Employee_Id] INT NULL, CONSTRAINT [FK_Employees_Hierarchy_1_Employees_Employee_Id] FOREIGN KEY ( [Employee_Id]) REFERENCES [dbo].[Employees] ([Employee_Id]), CONSTRAINT [FK_Employees_Hierarchy_1_Employees_Parent_Employee_Id] FOREIGN KEY ( [Parent_Employee_Id]) REFERENCES [dbo].[Employees] ([Employee_Id]), CONSTRAINT [FK_Employees_Hierarchy_1] FOREIGN KEY ( [Parent_Employee_Id]) REFERENCES [dbo].[Employees_Hierarchy_1] ([Employee_Id]) ) GO INSERT INTO [dbo].[Employees_Hierarchy_1] ( [Employee_Id], [Parent_Employee_Id] ) SELECT [Employee_Id], [Manager_Id] FROM [#Data] GO SELECT * FROM [dbo].[Employees_Hierarchy_1] GO

We can bind it back together using two joins between the main data table and hierarchy table:
SELECT e.[Employee_Id], e.[Name], pe.[Employee_Id], pe.[Name] FROM [dbo].[Employees_Hierarchy_1] [eh1] INNER JOIN [dbo].[Employees] [e] ON [e].[Employee_Id] = [eh1].[Employee_Id] LEFT JOIN [dbo].[Employees] pe ON pe.[Employee_Id] = [eh1].[Parent_Employee_Id] GO

We will verify it using the recursive CTE again:
;WITH [c] AS ( SELECT e.[Employee_Id], e.[Name], eh1.[Parent_Employee_Id], CAST(NULL AS NVARCHAR(100)) [Parent_Employee_Name], 1 [Level], CAST([Name] AS NVARCHAR(MAX)) AS [Path] FROM [dbo].[Employees_Hierarchy_1] eh1 INNER JOIN dbo.[Employees] e ON [e].[Employee_Id] = [eh1].[Employee_Id] WHERE eh1.[Parent_Employee_Id] IS NULL UNION ALL SELECT [e].[Employee_Id], [e].[Name], [eh1].[Parent_Employee_Id], [e].[Name], [c].[Level] + 1, [c].[Path] + '->' + [e].[Name] FROM [dbo].[Employees_Hierarchy_1] eh1 INNER JOIN [c] ON [c].[Employee_Id] = [eh1].[Parent_Employee_Id] INNER JOIN [dbo].[Employees] e ON [e].[Employee_Id] = [eh1].[Employee_Id] ) SELECT [c].[Employee_Id], [c].[Name], [c].[Parent_Employee_Id], [c].[Parent_Employee_Name], [c].[Level], [c].[Path] FROM [c] ORDER BY 1 GO
This solution may look as it’s more complicated, with more tables and joins at first look. That’s right. But it may have various advantages if we will think about it from the data modification point of view. We can edit employees separately from their hierarchy. We can optimize the hierarchy for searching, nodes movements, etc. much easier in a dedicated table. I will come back to it in a related post.
Moving the hierarchy to a real closure table (parent/node columns switch)
The second option how to move the hierarchy to a separated table is very similar to the first one. The main difference is that the [Parent_Employee_Id] is moved to be the first column in the table and it’s forming a unique primary key with the [Employee_Id] column.
CREATE TABLE [dbo].[Employees_Hierarchy_2] ( [Parent_Employee_Id] INT NOT NULL, [Employee_Id] INT NOT NULL, [Depth] INT NOT NULL, CONSTRAINT [PK_Employees_Hierarchy_2] PRIMARY KEY CLUSTERED ([Parent_Employee_Id], [Employee_Id]), CONSTRAINT [FK_Employees_Hierarchy_2_Employees_Parent_Employee_Id] FOREIGN KEY ( [Parent_Employee_Id]) REFERENCES [dbo].[Employees] ([Employee_Id]), CONSTRAINT [FK_Employees_Hierarchy_2_Employees_Employee_Id] FOREIGN KEY ( [Employee_Id]) REFERENCES [dbo].[Employees] ([Employee_Id]) ) GO
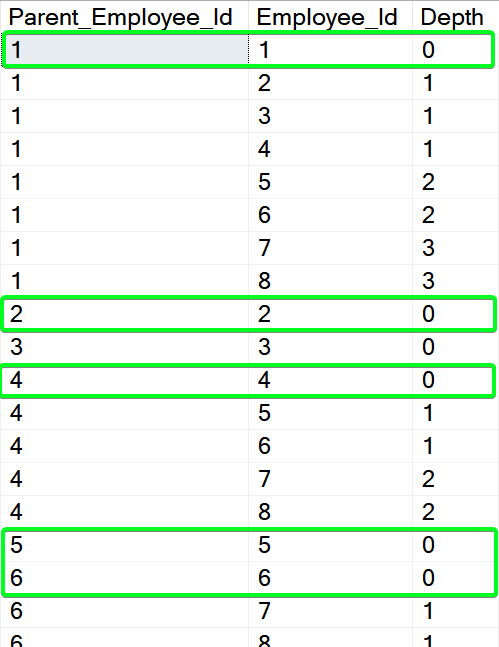
We need to adjust the data load process. We can’t import the data as is because the two top-level nodes (AMY and LAURE) haven’t a manager assigned (NULL value). This will lead to an error when we will try to insert NULL or duplicated value to the unique primary key. To override it we will generate self-referencing parents for top-level nodes. Same time we will generate a self-referencing node for every employee.
;WITH [c] AS ( SELECT [d].[Employee_Id] [Manager_Id], [d].[Employee_Id], 0 AS [Depth], CAST([d].[Name] AS NVARCHAR(MAX)) [Name] FROM [#Data] [d] UNION ALL SELECT [c].[Manager_Id], [d].[Employee_Id], [c].[Depth] + 1, [c].[Name] + '->' + [d].[Name] FROM [#Data] [d] INNER JOIN [c] ON [d].[Manager_Id] = [c].[Employee_Id] ) INSERT INTO [dbo].[Employees_Hierarchy_2] ( [Parent_Employee_Id], [Employee_Id], [Depth] ) SELECT [c].[Manager_Id], [c].[Employee_Id], [c].[Depth] FROM [c] GO SELECT * FROM [dbo].[Employees_Hierarchy_2] GO
The new [Depth] column is one of the biggest benefits the closure table approach is bringing to us. In combination with self-referencing nodes it allows us very effectively search for all nodes at a given dept-level in a hierarchy:
SELECT [h].[Parent_Employee_Id], [pe].[Name], [e].[Employee_Id], [e].[Name] FROM [dbo].[Employees_Hierarchy_2] [h] INNER JOIN [dbo].[Employees] [e] ON [e].[Employee_Id] = [h].[Employee_Id] INNER JOIN [dbo].[Employees] [pe] ON [pe].[Employee_Id] = [h].[Parent_Employee_Id] WHERE [h].[Depth] = 3 GO
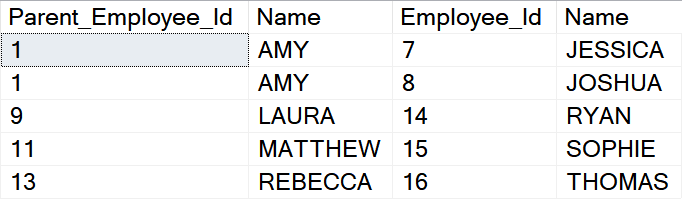
If you will check the data returned with the visual presentation of the hierarch above it’s pretty good visible that we have obtained all employees that are in the distance of 3 levels from their parents.
See more in related links below on how to mine as much as possible from the closure tables concept.
Nested Set
Nested Sets or the Nested Set Model is another technique how to store hierarchical data. It’s using the concept of left and right bowers to number nodes according to tree traversal navigation. I will recommend reading the Wiki for more information because this option isn’t as intuitive as the others. I have prepared the sample using an amazing CTE-based solution published by Jeff Moden. Read it for more details on how exactly the nested set’s generator works.
CREATE TABLE [#Tally] ([N] INT NOT NULL PRIMARY KEY)
;WITH [Tally] ([N]) AS
(
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) [a] ([n])
CROSS JOIN (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) [b] ([n])
CROSS JOIN (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) [c] ([n])
)
INSERT INTO [#Tally] ([N])
SELECT * FROM [Tally]
GO
;WITH [c] AS
(
SELECT [Employee_Id], [Manager_Id], 1 AS [Level], CAST(CAST([Employee_Id] AS BINARY(4)) AS VARBINARY(4000)) AS [Sort]
FROM [#Data]
WHERE [Manager_Id] IS NULL
UNION ALL
SELECT [e].[Employee_Id], [e].[Manager_Id], [c].[Level] + 1, CAST([c].[Sort] + CAST([e].[Employee_Id] AS BINARY(4)) AS VARBINARY(4000))
FROM [#Data] [e]
INNER JOIN [c] ON [c].[Employee_Id] = [e].[Manager_Id]
)
SELECT
ISNULL([Employee_Id], 0) [Employee_Id], [Manager_Id], ISNULL([Level], 0) [Level],
ISNULL(CAST(0 AS INT),0) [LeftBower], ISNULL(CAST(0 AS INT),0) [RightBower],
ROW_NUMBER() OVER (ORDER BY [Sort]) [NodeNumber],
ISNULL(CAST(0 AS INT),0) [NodeCount], ISNULL([Sort],[Sort]) [Sort]
INTO [dbo].[Employees_NestedSets]
FROM [c]
OPTION (MAXRECURSION 0)
DECLARE @LeftBower INT;
;WITH [c] AS
(
SELECT CAST(SUBSTRING([h].[Sort],[t].[N],4) AS INT) [Employee_Id],
COUNT(*) [NodeCount]
FROM [dbo].[Employees_NestedSets] [h], [#Tally] [t]
WHERE [t].[N] BETWEEN 1 AND DATALENGTH([h].[Sort])
GROUP BY SUBSTRING([h].[Sort], [t].[N], 4)
)
UPDATE [h]
SET @LeftBower = [LeftBower] = 2 * [NodeNumber] - [Level],
[h].[NodeCount] = [c].[NodeCount],
[h].[RightBower] = ([c].[NodeCount] - 1) * 2 + @LeftBower + 1
FROM [dbo].[Employees_NestedSets] [h]
INNER JOIN [c] ON [h].[Employee_Id] = [c].[Employee_Id]
ALTER TABLE [dbo].[Employees_NestedSets] ADD CONSTRAINT [PK_Employees_NestedSets] PRIMARY KEY CLUSTERED ([LeftBower], [RightBower])
CREATE UNIQUE INDEX [UX_Employees_NestedSets] ON [dbo].[Employees_NestedSets] ([Employee_Id])
ALTER TABLE [dbo].[Employees_NestedSets] ADD CONSTRAINT [FK_Employees_NestedSets_Employees_NestedSets_Manager_Id] FOREIGN KEY ([Manager_Id]) REFERENCES [dbo].[Employees_NestedSets] ([Employee_Id])
SELECT * FROM [dbo].[Employees_NestedSets]
GO
We have created [#Tally] table with 1000 numbers to support quick processing for CTEs following. The final result set is generated into [dbo].[Employees_NestedSets] and this table is enriched with some constraints to enforce data consistency and support search performance.
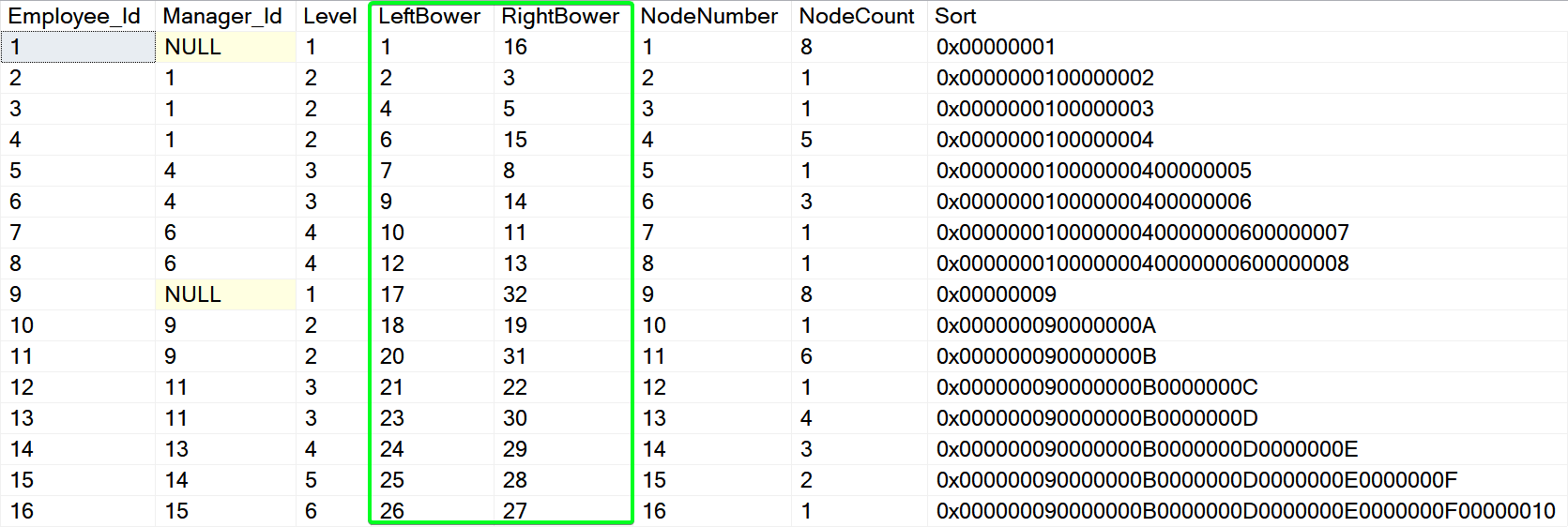
Green marked columns are responsible for the magic. These are the left and right boundary values used for navigation in the hierarchy. I.e., we would like to get the full path for THOMAS. There is no need for recursive CTE like with parent/child or other options. We will perform a simple WHERE condition search using the BETWEEN operator and concatenate Employee names using STRING_AGG() function into the final path:
DECLARE @ThomasLB INT SELECT @ThomasLB = [LeftBower] FROM [dbo].[Employees_NestedSets] [h] INNER JOIN [#Data] [e] ON [e].[Employee_Id] = [h].[Employee_Id] WHERE [e].[Name] = 'THOMAS' SELECT STRING_AGG([e].[Name], '=>') WITHIN GROUP (ORDER BY [h].[Level]) [Path] FROM [dbo].[Employees_NestedSets] [h] INNER JOIN [#Data] [e] ON [e].[Employee_Id] = [h].[Employee_Id] WHERE @ThomasLB BETWEEN [LeftBower] AND [RightBower] GO
![]()
Amazing, right? But every solution has its own pros and cons so read the article carefully. For nested sets, the complexity is mainly at the level of data modifications when bowers should be recalculated.
XML
Storing hierarchical data in XML format is easy. XML is designed to be a set of nested nodes by its nature and it is natively supported in SQL Server.
We will build the hierarchical XML nodes tree using a recursive scalar function. Because temporary tables cannot be used in scalar functions we need to move data from the [#Data] table to the physical table [dbo].[Data]. Finally, FOR XML PATH will do the jobs and convert the dataset to an XML tree.
SELECT *
INTO [dbo].[Data]
FROM [#Data]
GO
CREATE OR ALTER FUNCTION [SelectChild] (
@key AS INT
)
RETURNS XML
BEGIN
RETURN (
SELECT
[Employee_Id] AS '@Id', [Name] AS '@Name',
[dbo].[SelectChild]([Employee_Id])
FROM [Data]
WHERE [Manager_Id] = @key
FOR XML PATH('Employee'), TYPE
)
END
GO
SELECT
[Employee_Id] AS '@Id', [Name] AS '@Name',
[dbo].[SelectChild]([Employee_Id])
FROM [Data]
WHERE [Manager_Id] IS NULL
FOR XML PATH ('Employee'), ROOT('Employees')
GO
And the XML:
<Employees>
<Employee Id="1" Name="AMY">
<Employee Id="2" Name="DANIEL" />
<Employee Id="3" Name="EMILY" />
<Employee Id="4" Name="HANNAH">
<Employee Id="5" Name="JACK" />
<Employee Id="6" Name="JAMES">
<Employee Id="7" Name="JESSICA" />
<Employee Id="8" Name="JOSHUA" />
</Employee>
</Employee>
</Employee>
<Employee Id="9" Name="LAURA">
<Employee Id="10" Name="LUKE" />
<Employee Id="11" Name="MATTHEW">
<Employee Id="12" Name="OLIVIA" />
<Employee Id="13" Name="REBECCA">
<Employee Id="14" Name="RYAN">
<Employee Id="15" Name="SOPHIE">
<Employee Id="16" Name="THOMAS" />
</Employee>
</Employee>
</Employee>
</Employee>
</Employee>
</Employees>
To be honest: This is just a demonstration. It will have poor performance and huge complexity in case of large hierarchies and various data modifications like nodes movement. But it might be a really good format for a simple exchange of hierarchical data structure between SQL Server and different database platforms, API, or external data sources.
JSON
With the JSON is the situation exactly the same as with the XML. We will change the scalar function to work with JSON instead of XML using FOR JSON PATH clause. All the rest is similar.
CREATE OR ALTER FUNCTION [SelectChild_JSON] (
@key AS INT
)
RETURNS NVARCHAR(MAX)
BEGIN
RETURN (
SELECT
[Employee_Id] AS 'Id',
[Name] AS 'Name',
JSON_QUERY((SELECT [dbo].[SelectChild_JSON]([Employee_Id]))) [Employees]
FROM [Data]
WHERE [Manager_Id] = @key
FOR JSON PATH
)
END
GO
SELECT
[Employee_Id] AS 'Id', [Name] AS 'Name',
JSON_QUERY((SELECT [dbo].[SelectChild_JSON]([Employee_Id]))) [Employees]
FROM [Data]
WHERE [Manager_Id] IS NULL
FOR JSON PATH, ROOT( 'Employees')
GO
And the JSON:
{
"Employees": [
{ "Id": 1, "Name": "AMY",
"Employees": [ { "Id": 2, "Name": "DANIEL" },
{ "Id": 3, "Name": "EMILY" },
{ "Id": 4, "Name": "HANNAH",
"Employees": [ { "Id": 5, "Name": "JACK" },
{ "Id": 6, "Name": "JAMES",
"Employees": [ { "Id": 7, "Name": "JESSICA" },
{ "Id": 8, "Name": "JOSHUA" }
]
}
]
}
]
},
{ "Id": 9, "Name": "LAURA",
"Employees": [ { "Id": 10, "Name": "LUKE" },
{ "Id": 11, "Name": "MATTHEW",
"Employees": [ { "Id": 12, "Name": "OLIVIA" },
{ "Id": 13, "Name": "REBECCA",
"Employees": [ { "Id": 14, "Name": "RYAN",
"Employees": [ { "Id": 15, "Name": "SOPHIE",
"Employees": [ { "Id": 16, "Name": "THOMAS" }]
}
]
}
]
}
]
}
]
}
]
}
Nothing will change from the XML format regarding the complexity of processing and modifying.
HierarchyId Data Type
HiearachyId is the only real natively supported structure for handling hierarchical data in SQL Server. It’s implemented using CLR and you can read more on it in the documentation.
We will create [dbo].[Employees_Hierarchy_Id] where the [Path] column is of the HIERARCHYID type. Next, we will prepare the value for the [Path] column in a recursive CTE: [Employee_Id] column values will be converted to a string and contacted to form the path value which is then inserted into the [Path] column. the ‘All’ node will be created to make the example completed with one master node but this is just for demonstration, it will perfectly work with two parent nodes too.
CREATE TABLE [dbo].[Employees_Hierarchy_Id]
(
[Employee_Id] INT NOT NULL PRIMARY KEY,
[Name] NVARCHAR(100) NOT NULL,
[Path] HIERARCHYID NOT NULL
CONSTRAINT UC_Employees_Hierarchy_Id_Path UNIQUE NONCLUSTERED ([Path])
)
GO
;WITH [c] AS
(
SELECT [Employee_Id], [Name], CAST('/' AS NVARCHAR(MAX)) + CAST([Employee_Id] AS NVARCHAR(MAX)) + '/' [Path]
FROM [#Source]
WHERE [Manager] IS NULL
UNION ALL
SELECT [d].[Employee_Id], [d].[Name], [c].[Path] + CAST([d].[Employee_Id] AS NVARCHAR(MAX)) + '/' AS [Path]
FROM [#Source] [d]
INNER JOIN [c] ON [c].[Name] = [d].[Manager]
)
INSERT INTO [dbo].[Employees_Hierarchy_Id]
( [Employee_Id], [Name], [Path] )
SELECT
[c].[Employee_Id], [c].[Name], [c].[Path]
FROM [c]
GO
INSERT INTO [dbo].[Employees_Hierarchy_Id]
( [Employee_Id], [Name], [Path] )
SELECT 0, 'All', '/'
GO
SELECT
[h].[Employee_Id], [h].[Name], [h].[Path],
[h].[Path].ToString() [Path_String], [h].[Path].GetLevel() [Level],
[p].[Name] [Manager_Name], [h].[Path].GetAncestor(1).ToString() [Manager_Path]
FROM [dbo].[Employees_Hierarchy_Id] [h]
LEFT JOIN [dbo].[Employees_Hierarchy_Id] [p] ON [p].[Path] = [h].[Path].GetAncestor(1)
GO
Our hierarchy is now stored in the HIERARCHYID datatype column. We have also concerted the binary path value to human-readable form using the .ToString(). Please note the .GetLevel() function returning at which level the current node is. Then .GetAncestor() function was used to get the right Manager name.
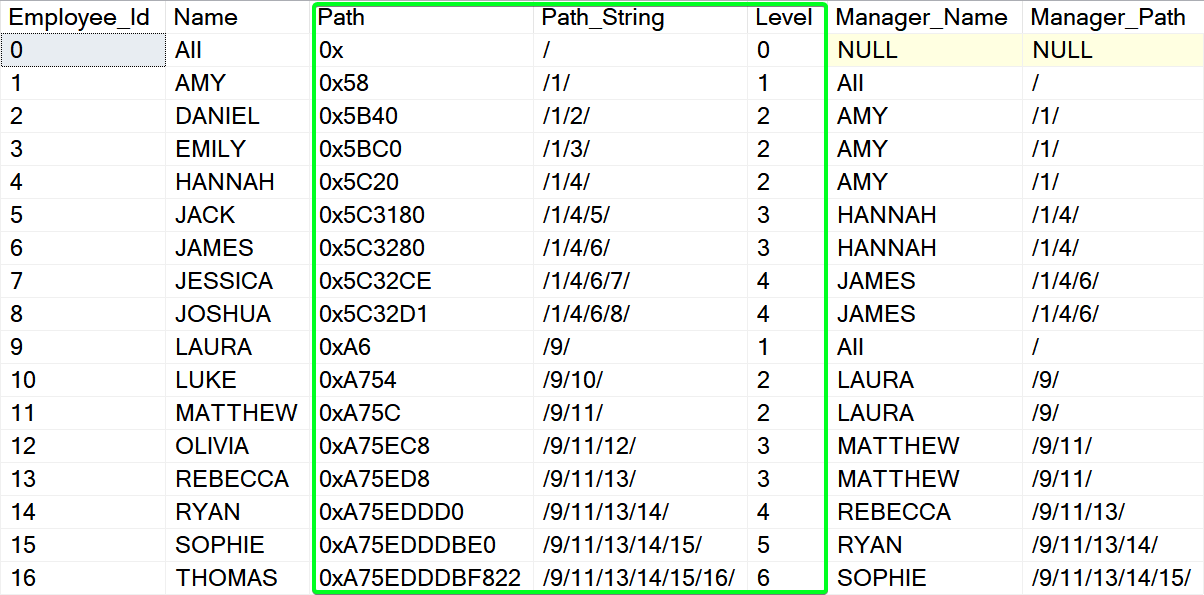
We can use the recursive CTE similarly to the options above and build the real path visually:
;WITH [c] AS (
SELECT [Employee_Id], [Name], [Path] [Parent_Path], CAST('/' + [Name] AS NVARCHAR(MAX)) [String_Path]
FROM [dbo].[Employees_Hierarchy_Id]
WHERE [Path].[GetAncestor](1) = 0x
UNION ALL
SELECT [eh].[Employee_Id], [eh].[Name], [Path], [c].[String_Path] + '/' + [eh].[Name]
FROM [dbo].[Employees_Hierarchy_Id] [eh]
INNER JOIN [c] ON [eh].[Path].[GetAncestor](1) = [c].[Parent_Path]
)
SELECT *
FROM [c]
GO

There is much more fun we can do with the HIERARCHYID data type column. It’s mostly compared to the Parent/Child approach. You should check it in the documentation or internet for usage/performance comparison and carefully decide which option will better fit your needs.
Graph
Grap–databases capabilities were added to SQL Server 2017 version. They are primarily designed to support the persistence and querying of complex relationships in data. But we can use it for parent-child relations too.
Lets create [dbo].[Employees] as NODEs table and [dbo].[IsManagerFor] as EDGE table. The NODEs table will store just a list of all employees. The EDGEs table will persist relations between employees. It’s very similar to the concept of moving the hierarchy outside of the primary table in the Closure tables chapter above.
CREATE TABLE [dbo].[Employees] (
[Employee_Id] INT PRIMARY KEY,
[Name] NVARCHAR(100) NOT NULL
) AS NODE
GO
CREATE TABLE [dbo].[IsManagerFor] AS EDGE;
GO
INSERT INTO [dbo].[Employees]
( [Employee_Id], [Name] )
SELECT
[Employee_Id], [Name]
FROM [#Data]
GO
INSERT INTO [dbo].[IsManagerFor]
( $from_id, $to_id )
SELECT
(SELECT $node_id FROM [dbo].[Employees] WHERE [Employee_Id] = [d].[Employee_Id]),
(SELECT $node_id FROM [dbo].[Employees] WHERE [Employee_Id] = [d].[Manager_Id])
FROM [#Data] [d]
WHERE [d].[Manager_Id] IS NOT NULL
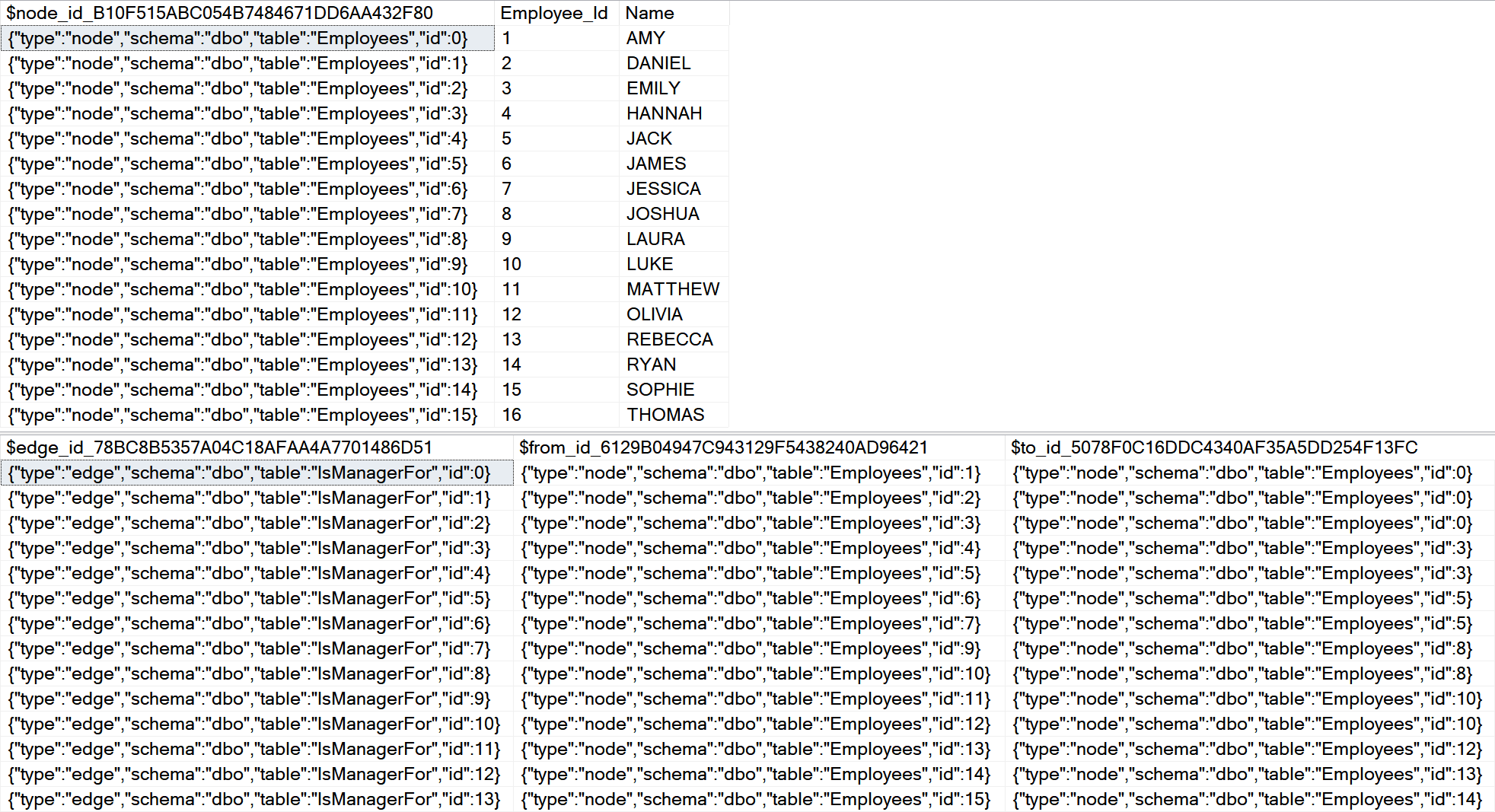
SELECT * FROM [dbo].[Employees]
SELECT * FROM [dbo].[IsManagerFor]
GO
If we will select nodes and edges new columns are presented: $node_id column is basically the new graph-specific unique id of an Employee. The edge is just and relation $from_id to $to_id node.
We can use the graph MATCH() function in WHERE clause to get a Manager for each Employee.
SELECT [e1].[Employee_Id], [e1].[Name] [Employee], [e2].[Employee_Id] [Manager_Id], [e2].[Name] [Manager] FROM [dbo].[Employees] [e1], [dbo].[IsManagerFor], [dbo].[Employees] [e2] WHERE MATCH([e1]-([IsManagerFor])->[e2]) GO
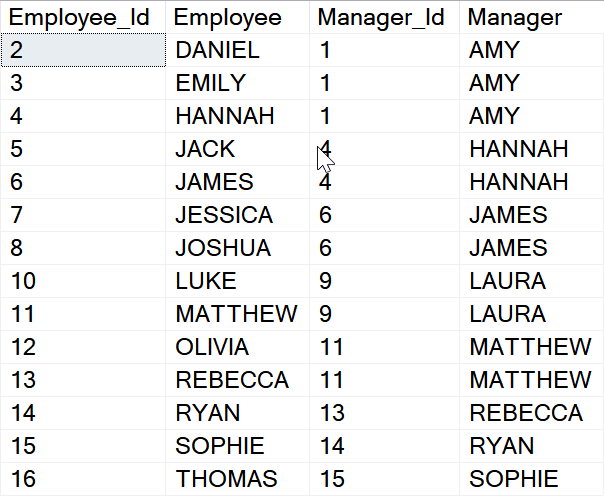
Recursive CTE can be used to get the hierarchy visually:
;WITH [c] AS ( SELECT [e].$node_id [Node_Id], [e].[Employee_Id], [e].[Name], 1 [Level], [m].$from_id [Parent_Node_Id], CAST([Name] AS NVARCHAR(MAX)) AS [Path] FROM [dbo].[Employees] [e] LEFT JOIN [dbo].[IsManagerFor] [m] ON [e].$node_id = [m].$from_id WHERE [m].$to_id IS NULL UNION ALL SELECT [e].$node_id, [e].[Employee_Id], [e].[Name], [c].[Level] + 1, [m].$to_id, [c].[Path] + '->' + [e].[Name] FROM [dbo].[IsManagerFor] [m] INNER JOIN [dbo].[Employees] [e] ON [m].$from_Id = [e].$node_id INNER JOIN [c] ON [c].[Node_Id] = [m].$to_Id ) SELECT * FROM [c] ORDER BY [c].[Employee_Id] GO
See graph specific nodes in the list:

You will aks probably where is the advantage to other options in this simple case. There is none. The EDGEs table is just a dedicated table like in the case of closure tables. The real value will come in the case of multiple different relations ships between employees (i.e. adding IsFriendOf). I will recommend this article to start with.
That’s all for now. I was trying to keep it as simple as possible to just demonstrate available options.
I will maintain this list of links over time for you to get more in-depth.
Links
Adjacency list (Parent/Child)
- https://en.wikipedia.org/wiki/Adjacency_list
- https://blog.duncanworthy.me/sql/hierarchical-data-pt1-adjacency-list/
- https://explainextended.com/2009/09/25/adjacency-list-vs-nested-sets-sql-server/
- https://www.sqlservercentral.com/articles/hierarchies-on-steroids-1-convert-an-adjacency-list-to-nested-sets
Closure tables
- https://www.red-gate.com/simple-talk/databases/sql-server/t-sql-programming-sql-server/sql-server-closure-tables/
Nested sets
- https://www.sqlservercentral.com/articles/hierarchies-on-steroids-2-a-replacement-for-nested-sets-calculations-1
HierarchyId
- https://docs.microsoft.com/en-us/sql/t-sql/data-types/hierarchyid-data-type-method-reference?view=sql-server-ver15
- https://docs.microsoft.com/en-us/sql/relational-databases/tables/tutorial-using-the-hierarchyid-data-type?view=sql-server-ver15
- https://www.sqlshack.com/use-hierarchyid-sql-server/
- https://blog.matesic.info/post/HierarchyID-data-type-performance-tips-and-tricks
Graph
- https://www.red-gate.com/simple-talk/databases/sql-server/t-sql-programming-sql-server/sql-server-graph-databases-part-1-introduction