
There isn’t built-in support for working with hierarchies in the SQL Server except for the hierarchyid data type. This means that we should solve most of the hierarchical data processing tasks using the old-school portfolio of standard T-SQL language. One of these tasks is a simple conversion of hierarchical paths represented as a string to a classic parent-child table. There are a few options for how to do it. One of them is based on the replacement of the string using CHARINDEX(). I don’t like this function because it’s limited by the condition that every part of the path must be unique and it can’t be easily extended or reused for further processing of the hierarchy. Thus I was thinking about a more flexible solution.
Let’s start with some sample data. I will use the traditional example with the hierarchy of people like managers-employees or company organizational tree.
DROP TABLE IF EXISTS [#Source]
CREATE TABLE [#Source] ( [Path] NVARCHAR(MAX) NOT NULL )
INSERT INTO [#Source]
( [Path] )
SELECT 'AMY' UNION ALL
SELECT 'AMY/DANIEL' UNION ALL
SELECT 'AMY/EMILY' UNION ALL
SELECT 'AMY/HANNAH' UNION ALL
SELECT 'AMY/HANNAH/JACK' UNION ALL
SELECT 'AMY/HANNAH/JAMES' UNION ALL
SELECT 'AMY/HANNAH/JAMES/JESSICA' UNION ALL
SELECT 'AMY/HANNAH/JAMES/JOSHUA' UNION ALL
SELECT 'LAURA' UNION ALL
SELECT 'LAURA/LUKE' UNION ALL
SELECT 'LAURA/MATTHEW' UNION ALL
SELECT 'LAURA/MATTHEW/OLIVIA' UNION ALL
SELECT 'LAURA/MATTHEW/REBECCA' UNION ALL
SELECT 'LAURA/MATTHEW/REBECCA/RYAN' UNION ALL
SELECT 'LAURA/MATTHEW/REBECCA/RYAN/SOPHIE' UNION ALL
SELECT 'LAURA/MATTHEW/REBECCA/RYAN/SOPHIE/THOMAS'
SELECT * FROM [#Source]
GO
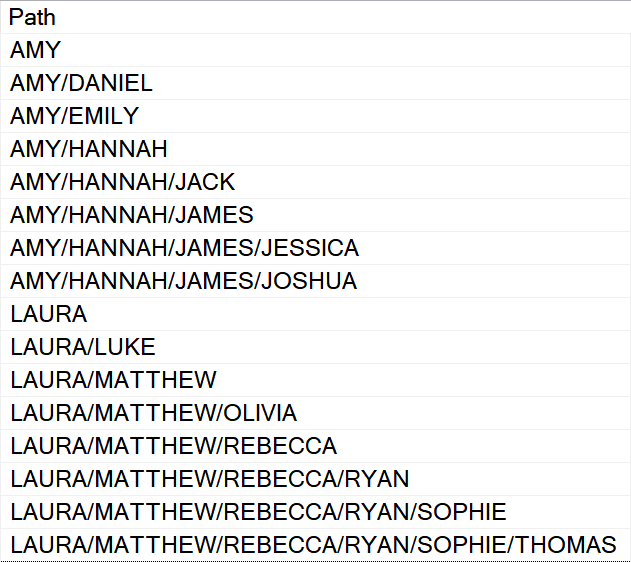
There are two top-level nodes (AMY, LAURA) marked and they have a different number of child levels. I keep names to be unique to make it simple but the code following works properly for nodes of the same level in a different hierarchy path too.
Let’s do the first processing step: split path string to rows and calculate some useful values we will use later.
DROP TABLE IF EXISTS [#PathsCache]
CREATE TABLE [#PathsCache] (
[Id] INT NOT NULL PRIMARY KEY IDENTITY(1,1),
[Path] NVARCHAR(MAX) COLLATE Czech_CI_AS NULL,
[Path_Hash] BINARY(32) NULL,
[Node_Name] NVARCHAR(MAX) COLLATE Czech_CI_AS NULL,
[Level] TINYINT NOT NULL,
[Depth] TINYINT NULL,
[Parent_Path] NVARCHAR(MAX) COLLATE Czech_CI_AS NULL,
[Parent_Path_Hash] BINARY(32) NULL,
UNIQUE NONCLUSTERED ([Path_Hash], [Level])
)
INSERT INTO [#PathsCache]
( [Path], [Path_Hash], [Node_Name], [Level] )
SELECT
[src].[Path], HASHBYTES('SHA2_256', [src].[Path]), [l].[Value], CAST([l].[Key] AS INT)
FROM [#Source] [src]
OUTER APPLY OPENJSON(N'["' + REPLACE([src].[Path], N'/', N'","') + N'"]') [l]
ORDER BY [src].[Path], CAST([l].[Key] AS INT)
UPDATE [t]
SET [t].[Depth] = [l].[Depth]
FROM [#PathsCache] [t]
OUTER APPLY ( SELECT MAX([l].[Level]) [Depth]
FROM [#PathsCache] [l]
WHERE [l].[Path] = [t].[Path]
) [l]
;WITH [c] AS
(
SELECT
[Id], [Node_Name], [Path_Hash], [Level], CAST([Node_Name] AS NVARCHAR(MAX)) [Parent_Path]
FROM [#PathsCache]
WHERE [Level] = 0
UNION ALL
SELECT
[t].[Id], [t].[Node_Name], [c].[Path_Hash], [t].[Level], [c].[Parent_Path] + N'/' + [t].[Node_Name]
FROM [c]
INNER JOIN [#PathsCache] [t] ON [t].[Path_Hash] = [c].[Path_Hash] AND [t].[Level] = [c].[Level] + 1
)
UPDATE [t]
SET [t].[Parent_Path] = [c].[Parent_Path],
[t].[Parent_Path_Hash] = HASHBYTES('SHA2_256', [c].[Parent_Path])
FROM [#PathsCache] [t]
LEFT JOIN [c] ON [c].[Path_Hash] = [t].[Path_Hash] AND [c].[Level] = [t].[Level] - 1
OPTION(MAXRECURSION 0)
SELECT * FROM [#PathsCache]
GO

I have marked lines doing the main part of the job:
- 20. – The OPENJSON() function is used to split the literal path into rows. You will say that STRING_SPLIT() function can be used but this has one major limitation: order of output rows isn’t guaranteed except in Azure SQL or Managed instance which makes this function unusable for on-premise SQL instances because we need rows to be sorted exactly as they appear in the original path string. Another disadvantage of the STRING_SPLIT() function is that the delimiter can be only a single character long which makes it risky that the path delimiter will be contained in node names too.
- 21. – Individual strings (Node_Names) for every single Path are sorted by Key column returned from the OPENJSON() function. This column maintains the original position of an item (node) in the JSON array (path).
- 24. – The Depth column value is updated to the maximum Level for every unique Path. If there is the same Depth and Level value on a row we know that this row is the leaf level of the current Path.
- 46. – CTE is used to calculate the parent path for every row (node). It’s the path without the name of the node itself. SUBSTRING() function can do the same (simply remove node name from the path), but this will cause an issue in a case where there are multiple nodes with the same name in a path. CTE brings a safe solution and data safety outperforms the potential performance hit. Sure there are other options like replacing strings from right to left. Just play with it.
Hashes are calculated and used to prepare the solution for performance testing on a large number of paths because the Path is using the NVARCHAR(MAX) datatype to have unlimited length. NVARCHAR(MAX) can’t be used in indexes and this may lead to a significant performance bottleneck for used JOIN operators. We can create unique constraints over the hash values column to enforce certain data integrity rules like disabling duplicated node names etc. too.
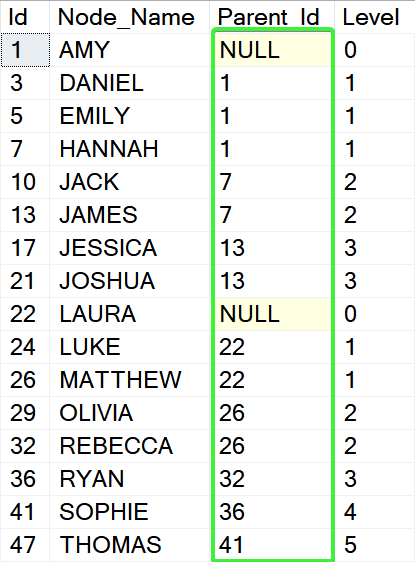
The final step is pretty easy: We will select all leaf nodes (row 14.) and insert them into the final parent-child table. Same time we will LEFT JOIN the table (row. 21) to get the Parent_Id value:
DROP TABLE IF EXISTS [#Hierarchy] CREATE TABLE [#Hierarchy] ( [Id] INT NOT NULL PRIMARY KEY, [Node_Name] NVARCHAR(MAX) NOT NULL, [Parent_Id] INT NULL, [Level] TINYINT ) ;WITH [c] AS ( SELECT [t].[Id], [t].[Node_Name], [t].[Path], [t].[Path_Hash], [t].[Parent_Path_Hash], [t].[Level] FROM [#PathsCache] [t] WHERE [t].[Level] = [t].[Depth] ) INSERT INTO [#Hierarchy] ( [Id], [Node_Name], [Parent_Id], [Level] ) SELECT [c].[Id], [c].[Node_Name], [p].[Id], ISNULL([p].[Level] + 1, 0) FROM [c] LEFT JOIN [c] [p] ON [p].[Path_Hash] = [c].[Parent_Path_Hash] SELECT * FROM [#Hierarchy] GO
And this is our brand new Parent-Child table created from a list of literal paths:
There is much more to do with. I.e it’s easy to search for paths that are in the set but the set doesn’t contain the parent node itself and more. A big chapter is a performance: The whole solution is built using the traditional data processing stack and every single part of it can be rewritten or optimized and the main idea will stay alive. I will bring more on this in another post later.