
It’s a common scenario in data processing solutions that we must import some data for further processing and we can’t dictate source format or data types used. This can complicate things, especially in the case when source data key values are in string format with untrivial length. Character data types used in unique keys may cause a lot of trouble when the data volume grows in time.
Still, there is one option on how to make our JOINs faster and save a significant amount of space. Let’s review it in real on the sample below. It’s preparing three tables with 1.000.000 of rows using 3 different data types to store the key value:
DROP TABLE IF EXISTS [dbo].[t_STRING]
DROP TABLE IF EXISTS [dbo].[t_BINARY]
DROP TABLE IF EXISTS [dbo].[T_INT]
CREATE TABLE [dbo].[t_STRING] (
[ValueKey] VARCHAR(200) NOT NULL PRIMARY KEY
)
CREATE TABLE [dbo].[t_BINARY] (
[ValueKey] BINARY(32) NOT NULL PRIMARY KEY
)
CREATE TABLE [dbo].[T_INT] (
[ValueKey] INT NOT NULL PRIMARY KEY
)
INSERT INTO [dbo].[t_STRING]
( [ValueKey] )
SELECT TOP 1000000
CAST([c1].[object_id] AS VARCHAR(10)) + CAST([c1].[column_id] AS VARCHAR(10)) +
CAST([c2].[object_id] AS VARCHAR(10)) + CAST([c2].[column_id] AS VARCHAR(10)) +
'=>' +
REPLICATE(CAST(NEWID() AS VARCHAR(36)), 4)
FROM [msdb].[sys].[columns] [c1]
CROSS JOIN [msdb].[sys].[columns] [c2]
ORDER BY [c1].[object_id], [c1].[column_id], [c2].[object_id], [c2].[column_id]
INSERT INTO [dbo].[t_BINARY]
( [ValueKey] )
SELECT
HASHtYTES('SHA2_256', [ValueKey])
FROM [dbo].[T_STRING]
GO
INSERT INTO [dbo].[T_INT]
( [ValueKey] )
SELECT
ROW_NUMBER() OVER(ORDER BY (SELECT NULL))
FROM [dbo].[t_STRING]
GO
SELECT TOP(5) * FROM [dbo].[t_STRING]
SELECT TOP(5) * FROM [dbo].[t_BINARY]
SELECT TOP(5) * FROM [dbo].[T_INT]
GO

We have created three new tables:
- t_STRING – this one holds a long string key value to simulated some artificial key we are receiving from the incoming data stream
- t_BINARY – it’s demonstrating the option that we can convert the long string key to a much smaller data type keeping it to be the unique same time
- T_INT – it’s there just for comparison to show the overhead between the ideal INT key and the BINARY(32) and VARCHAR(200) alternatives.
Let’s review the amount of storage used by each table:

It’s pretty clear that INT data type is the ideal solution with 13 MB to be used. The BINARY(32) needs 3x more storage to keep the same number of unique values. But if we will compare the BINARY(32) key to the VARCHAR(200) key it’s consuming only around 25% of the storage.
The JOIN
The smaller the data type is the less storage and buffer pool memory will be used and the better JOINs and other data set operations performance will the SQL Server engine deliver to us. Let’s test it on 1 million rows to be joined together:
SET STATISTICS TIME ON SET STATISTICS IO ON SELECT COUNT(*) Cnt FROM [t_STRING] [s1] INNER JOIN [dbo].[t_STRING] [s2] ON [s2].[ValueKey] = [s1].[ValueKey] OPTION(MAXDOP 1) SELECT COUNT(*) Cnt FROM [t_BINARY] [b1] INNER JOIN [dbo].[t_BINARY] [b2] ON [b2].[ValueKey] = [b1].[ValueKey] OPTION(MAXDOP 1) SELECT COUNT(*) Cnt FROM [T_INT] [i1] INNER JOIN [dbo].[t_INT] [i2] ON [i2].[ValueKey] = [i1].[ValueKey] OPTION(MAXDOP 1) GO
The result is:
- t_STRING – Scan count 2, logical reads 44712 with CPU time = 7188 ms, elapsed time = 7377 ms.
- t_BINARY – Scan count 2, logical reads 10264 with CPU time = 672 ms, elapsed time = 1241 ms.
- t_INT’. Scan count 2, logical reads 3230 with CPU time = 531 ms, elapsed time = 874 ms.
It’s clear that INT outperforms all other data types. But what’s impressive is that BINARY(32) is about 7x faster than VARCHAR(200). There is also a big difference in the number of logical reads from the warm cache. This will have also other significant advantages like much less memory used by the buffer pool or memory granted for the query to execute.
As you have probably noticed the query execution was limited to not use parallelism with the MAXDOP 1 hint. Let’s remove the hint, run queries again, and compare execution plans:
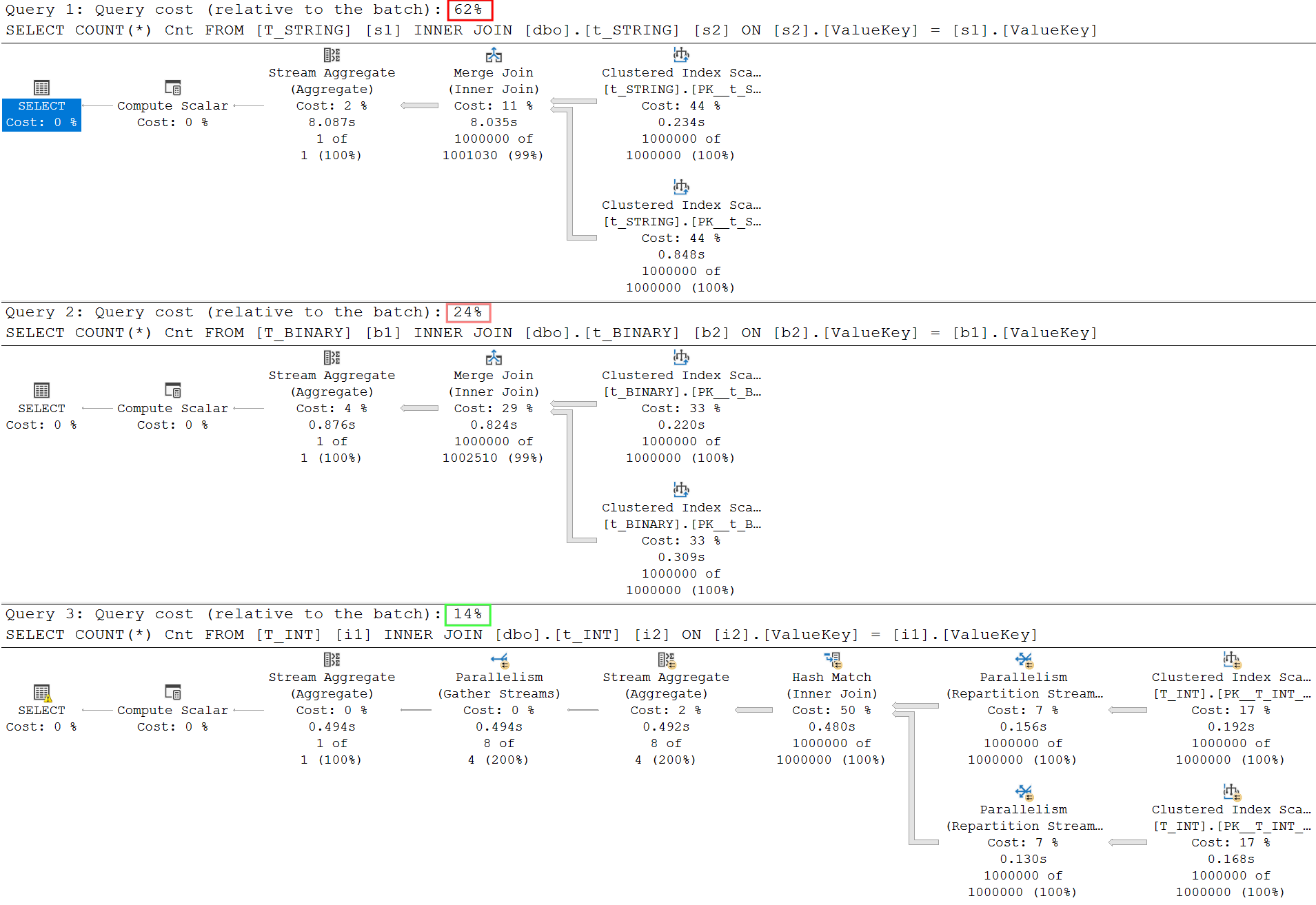
The major difference is there that parallelism was used in the case of the INT key. I don’t want to go deeper inside query optimizer but just wanted to show that the proper selection of key column data type may have a significant impact in the future.
The SEEK
Heavy JOINs like the above one is a common scenario in the DWH world. But what about simple SEEK operation most natural in OLTP processing? Let’s try it:
SET STATISTICS TIME ON
SET STATISTICS IO ON
--SELECT HASHBYTES('SHA2_256', '1711015754001=>1A15992D-3F76-42B6-AEBB-6C26912C59CF1A15992D-3F76-42B6-AEBB-6C26912C59CF1A15992D-3F76-42B6-AEBB-6C26912C59CF1A15992D-3F76-42B6-AEBB-6C26912C59CF')
SELECT * FROM [dbo].[t_STRING] WHERE [ValueKey] = '1711015754001=>1A15992D-3F76-42B6-AEBB-6C26912C59CF1A15992D-3F76-42B6-AEBB-6C26912C59CF1A15992D-3F76-42B6-AEBB-6C26912C59CF1A15992D-3F76-42B6-AEBB-6C26912C59CF'
SELECT * FROM [dbo].[t_BINARY] WHERE [ValueKey] = 0x21EB2407F26894DF8F4DE556D336BD910B705E81338EEEA63B2EBDA727FE3F46
SELECT * FROM [dbo].[t_INT] WHERE [ValueKey] = 450000
GO
We have performed 3 simple SEEK operations where all the time one row is returned. All 3 queries have execution time < 0ms and the only one difference is in the number of logical reads where VARCHAR(200) needs 4 logical reads to process the query and BINARY(32) and INT both 3 only. At the first look, it doesn’t seem to be a big difference but try to imagine a heavily loaded system with thousands of SEEK operations per second. This time it may have a significant impact on the performance.
What remains untested are range queries with a variable number of rows from lower tens to a few % of the total rows count. The rule is basic: the more rows, the more SEEK, and the bigger the impact of the VARCHAR(200) columns. BINARY(32) is also a good option there.
The BIGINT devil
Maybe you are thinking if there is some solution in the middle combining advantages of INT and BINARY(32). Maybe it’s but I’m mentioning it separately because even after advanced searching I’m not sure about the probability of unique values collision.
The solution is quite easy: it’s simply casting the BINARY(32) (HASB_BYTES result) to BIGINT. Let’s check this sample:
DROP TABLE IF EXISTS [dbo].[t_BIGINT]
CREATE TABLE [dbo].[T_BIGINT] (
[ValueKey] BIGINT NOT NULL PRIMARY KEY
)
INSERT INTO [dbo].[T_BIGINT]
( [ValueKey] )
SELECT
CAST(HASHBYTES('SHA2_256', [ValueKey]) AS BIGINT)
FROM [dbo].[T_STRING]
GO
The cast is on the highlighted row.
If we will compare the storage, it’s much closer to INT than to BINARY(32). This is obvious from the fact that BIGINT occupies only 8 bytes of store per value:

Where I see the hidden risk there is that BIGINT store only 8 bytes of information whereas HASH_BYTE() returns BINARY(32) value for the SHA2_256 algorithm.
It’s pretty good visible if we will cast the maximum value of BIGINT into BINARY(8): it will fit perfectly:
SELECT CAST(CAST(9223372036854775807 AS BIGINT) AS BINARY(8))
I can’t answer the mathematical level of probability that two BINARY(32) values will lead to collision when cast to BIGINT. That’s probably the devil inside this solution and that way I can’t recommend it if I will imagine the cost of a large DWH to be rebuilt with different data types for a significant amount of primary keys.
There is not much detailed discussion around this topic so you can read more on it.