
The OFFSET… FETCH NEXT extension to SELECT statement was introduced first in SQL Server 2012. It should basically support simple pagination of query results from the application. For large datasets, it’s really important to understand how it is internally implemented, and based on these findings, I won’t recommend using it for batch processing on the SQL Server side. There are more performant options and I will show you one of them.
For our testing purposes let’s build a sample table with 1 million integer values sequence ordered by value – this will just simulate the most common scenario when data in the paginated table are sorted by the primary clustered key.
DROP TABLE IF EXISTS [dbo].[SampleTable]
CREATE TABLE [dbo].[SampleTable] ([Id] INT NOT NULL PRIMARY KEY CLUSTERED)
INSERT INTO [dbo].[SampleTable] ( [Id])
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) [a]([n])
CROSS JOIN (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) [b]([n])
CROSS JOIN (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) [c]([n])
CROSS JOIN (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) [d]([n])
CROSS JOIN (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) [e]([n])
CROSS JOIN (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) [f]([n])
GO
We will execute 3 “pagination” queries against the table. They will return 100 rows each. The main difference is the starting position (OFFSET). It’s set to 0, 100 000, and 500 000 rows. We will check execution plans and collect basic query statistics for comparison.
SET STATISTICS IO ON SET STATISTICS TIME ON SELECT * FROM [dbo].[SampleTable] ORDER BY [Id] OFFSET 0 ROWS FETCH NEXT 100 ROWS ONLY SELECT * FROM [dbo].[SampleTable] ORDER BY [Id] OFFSET 100000 ROWS FETCH NEXT 100 ROWS ONLY SELECT * FROM [dbo].[SampleTable] ORDER BY [Id] OFFSET 500000 ROWS FETCH NEXT 100 ROWS ONLY GO

Red marked are execution times of individual queries. In the case of such a simple table with integer values, this is a huge difference. We can assume that it can be easily explained from the different numbers of logical read. If all the queries are the same and similar 100 rows are returned, where is this major logical reads difference coming from? Let’s check execution plans.
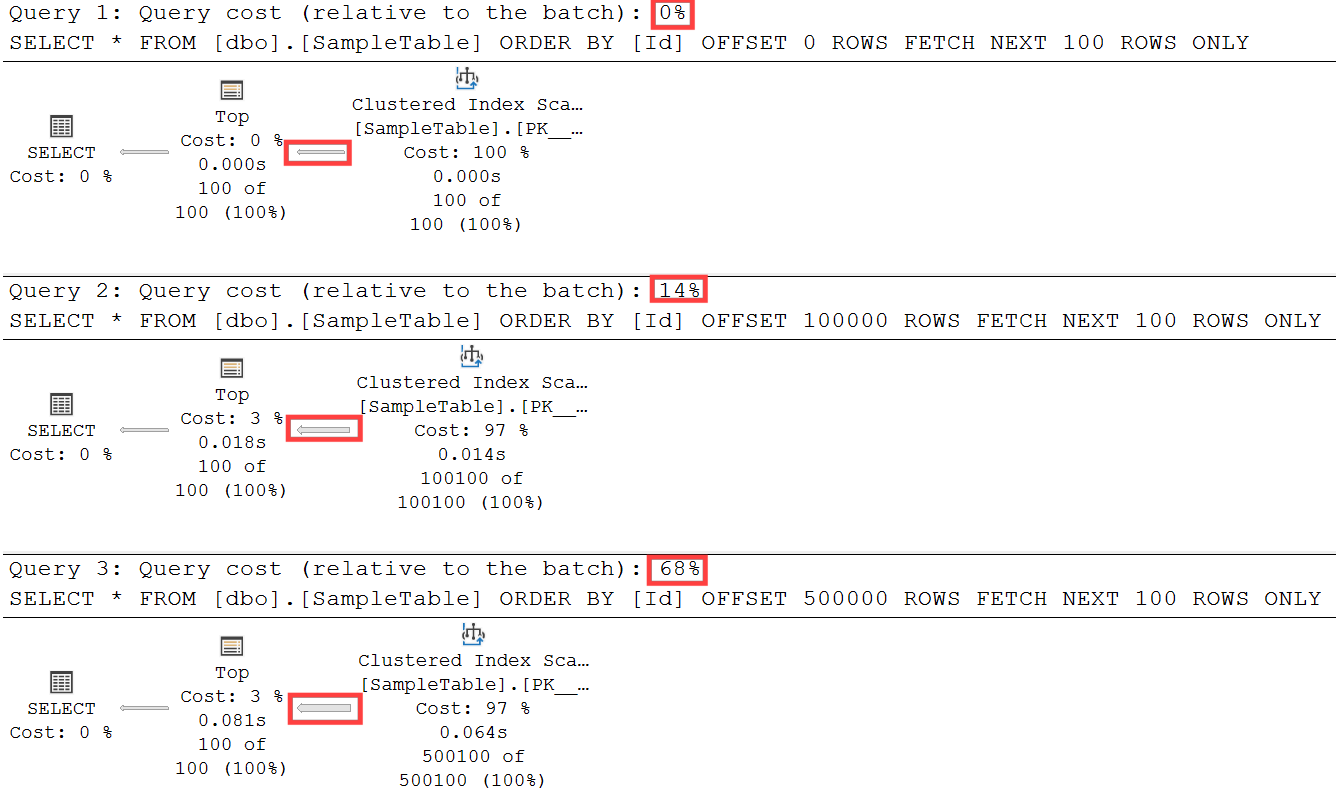
All three queries are using Clustered index scan operator but if you will check how thick is the output line from the Clustered Index Scan operator to the TOP operator, there is a big difference noticeable. When we will check in detail all three Scan operators, the following numbers are present:



Let me explain that. The FETCH_NEXT operator is using Clustered Index Scan operator to collect results and send them to the TOP operator. In the first query the scan is starting and the 1st row and is stopped when row 100 is reached. This is because the 0 OFFSET is specified. The next two queries on the other side have a large number of rows to be skipped specified in the OFFSET (100k, 500k). This means that using the Scan operator SQL Server needs to scan all these 100/500k rows to get to the position where the next 100 rows are located. There is no other way how to do that because SQL Server doesn’t understand the data itself to think like: I seek directly to row with the number 100 000 and get next 100 rows.
How can that behavior affect your application pagination? Let me show it in this very simple example: We will iterate our 1 million rows in 10 iterations and return 100k rows in every one of them. This is like we will simulate that user clicks in the application 10 times to get the next 100k rows displayed (sure that’ extreme case but makes it obvious what’s going on).
SET NOCOUNT ON
DECLARE @Iteration INT = 0
DECLARE @BatchSize INT = 100
DECLARE @StartTime DATETIME2(3)
WHILE @Iteration < 10
BEGIN
SET @StartTime = SYSDATETIME()
SELECT [Id]
FROM [dbo].[SampleTable]
ORDER BY [Id]
OFFSET @Iteration * 100000 ROWS FETCH NEXT @BatchSize ROWS ONLY
PRINT CAST(@Iteration * 100000 AS VARCHAR(10)) + ' => ' + CAST(DATEDIFF(ms, @StartTime, SYSDATETIME()) AS VARCHAR(10)) + ' ms'
SET @Iteration += 1
END
GO

It’s clearly visible from the execution time for each “click”: the bigger is the offset, the more pages we have already seen in the application, the slower is the operation to get a new set of rows for the next page.
I agree that this is an extreme demonstration of the behavior. But consider it in the case when the nature of the application requires a large number of pagination operations for many users simultaneously. Then it can lead to a heavy load.
Batch data processing
What I have demonstrated in the query above is also a common scenario when we would like to process a large number of rows directly in SQL Server routine and we need the result to be sorted. In our case, with the order sequence of numbers, there is a much better solution to do that and omit the excessive offset scanning and slowness of the overall process.
We will pre-generate all batches to go in one step and the main table will be queried using BETWEEN clause which will effectively seek for the wanted range of rows using the Index Seek operator (sure may be promoted to Scan operator in case of the batch is too large). The only question is how we will split the total amount of rows to be processed into several batches. In our case, I did it very simple with the NTILE() ranking function but any other and more complex method can be used based on data nature.
SET NOCOUNT ON DECLARE @ST DATETIME2(3) DECLARE @TotalRows INT DECLARE @BatchSize INT DECLARE @TilesNr INT DECLARE @BatchId INT DECLARE @FromId INT DECLARE @ToId INT SET @TotalRows = (SELECT COUNT(*) FROM [dbo].[SampleTable]) SET @BatchSize = 100 SET @TilesNr = @TotalRows / @BatchSize DECLARE @Batches TABLE ([BatchId] INT NOT NULL PRIMARY KEY, [FromId] INT NOT NULL, [ToId] INT NOT NULL, [RowsInBatchCnt] INT NOT NULL) INSERT INTO @Batches ( [BatchId], [FromId], [ToId], [RowsInBatchCnt] ) SELECT [BatchId], MIN([Id]), MAX([Id]), COUNT(*) FROM ( SELECT NTILE(@TilesNr) OVER(ORDER BY [Id]) [BatchId], [Id] FROM [dbo].[SampleTable] ) [a] GROUP BY [a].[BatchId] WHILE EXISTS (SELECT * FROM @Batches) BEGIN SELECT TOP(1) @BatchId = [BatchId], @FromId = [FromId], @ToId = [ToId] FROM @Batches ORDER BY [BatchId] PRINT @BatchId SET @ST = SYSDATETIME() SELECT * FROM [dbo].[SampleTable] WHERE [Id] BETWEEN @FromId AND @ToId PRINT CAST(@@ROWCOUNT AS VARCHAR(10)) + ' rows in ' + CAST(DATEDIFF(ms, @ST, CAST(SYSDATETIME() AS DATETIME2(3))) AS VARCHAR(10)) + ' ms' DELETE FROM @Batches WHERE [BatchId] = @BatchId END GO
When we will check the @Batches table variable content is looks like this:
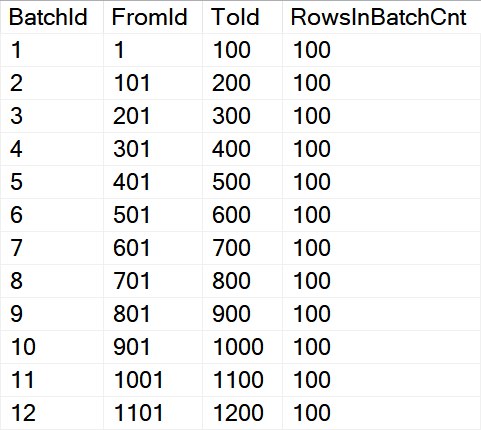
FromId and ToId values are used in the BETWEEN clause.
Performance-wise this solution is returning the next 100 rows all the time with the same performance. In this particular case under 0 ms independently on the number of the batch currently processed.

This kind of “pagination” may be also an option for the application in case the data volatility is relatively low, let’s say when the application is used to browse some precalculated data that is updated once a day and the number of ids to be cached is reasonable to fit into application cache.
The nature of the data
Finally, it’s important to say that this is an ideal world example because we have used a beautiful uninterrupted sequence of integer values. In a real-world scenario, this is a rare case, especially in the case of tables with IDENTITY values and applications using explicit transactions because the IDENTITY value gets increment in case of ROLLBACK too.
We can simulate it easily via deletion of a small range of rows from our sample table.
DELETE FROM [dbo].[SampleTable] WHERE [Id] BETWEEN 540 AND 760 GO SELECT * FROM [dbo].[SampleTable] ORDER BY [Id] OFFSET 500 ROWS FETCH NEXT 100 ROWS ONLY GO
The OFFSET…FETCH next will handle the situation properly and will fetch exactly 100 rows with ids between 501 and 539 and 761 and 821.
In the case of the batch processing scenario with the NTILE() used it’s a little bit more complicated: You can see it in the picture:
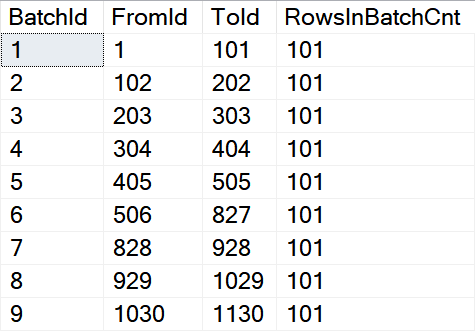
In row 6 we can see that there is the missing part of the sequence handled. But the number of rows in the batch has changed for several batches from 100 to 101 because the total number of rows has changed from the ideal 1 million and NTILE() is trying to divide it into batches with some approximation. I don’t want to go into deeper details now. The main message is that in the case of batch processing it’s very important to understand the nature of the data and if the sequence can be interrupted.
Further reading: