
APPROX_COUNT_DISTINCT() is a nice new function announced currently to be in public preview for Azure. Being well known for Oracle users is now joining (like many other things:)) also the Microsoft world.
This function is designed to provide aggregations across large data sets where responsiveness is more critical than absolute precision. It evaluates an expression for each row in a group and returns the approximate number of unique non-null values in a group.
It accepts an expression of any type, except image, sql_variant, ntext, or text.
Internally it’s optimized for use in big data scenarios for the following conditions:
- Access to data sets that are millions of rows or higher and
- Aggregation of a column or columns that have many distinct values
The function implementation guarantees up to a 2% error rate within a 97% probability using the HyperLogLog algorithm and requires less memory than an exhaustive COUNT DISTINCT operation. Having a smaller memory footprint will the function less likely to spill memory to disk compared to a precise COUNT DISTINCT operation.
Let us try in on AdwentureWorksLT sample database running on Azure SQL:
SELECT COUNT(DISTINCT [ProductID]) AS [Distinct_ProductIDs], APPROX_COUNT_DISTINCT([ProductID]) AS [Approx_Distinct_ProductIDs] FROM [SalesLT].[SalesOrderDetail] GO SELECT [ProductID], COUNT(DISTINCT [LineTotal]) AS [Distinct_Line_Total_Per_ProductID], APPROX_COUNT_DISTINCT([rowguid]) AS [Distinc_LineTotal_Per_ProductID] FROM [SalesLT].[SalesOrderDetail] GROUP BY [ProductID] ORDER BY [ProductID] GO
![]()
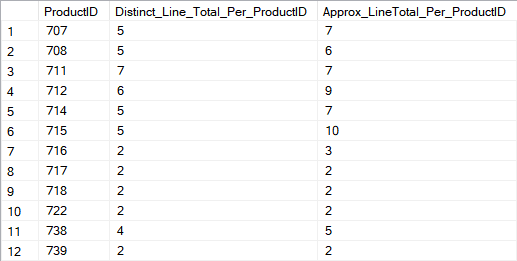
The result is quite interesting for anyone who will expect that for smaller data sets APPROX_COUNT_DISTINCT will return the same result as COUNT DISTINCT. Not exactly – significant differences are theRE, i.e. row 6 for Product_ID = 715 – there is double value to be approximated. So there is really no reason to not use COUNT DISTINCT for smaller data set where the overhead is minimal. APPROX_COUNT_DISTINCT will make a great job on a really large data set where we need to do raw estimates of rows count and running the precise COUNT DISTINCT will consume a huge amount of system resources.