Sparse columns in SQL Server are an intriguing feature designed to optimize storage for columns that contain a significant amount of NULL values. Introduced in SQL Server 2008, sparse columns offer a way to store nulls efficiently, consuming no storage space for NULL values in a column. This feature can be particularly useful in scenarios where the table has many columns that are not frequently used or that often contain null values. Sparse columns are ideal for situations where NULL values can constitute 20% to 40% or more of the dataset in a column. Beyond storage optimization, sparse columns also have implications for the performance of data retrieval and manipulation operations.
Internal Implementation and Metadata
Internally, SQL Server implements sparse columns by not physically storing NULL values. Non-NULL values in sparse columns consume more storage space than their non-sparse counterparts due to the overhead associated with maintaining sparsity. This trade-off means that while sparse columns can significantly reduce the storage footprint of highly null columns, they might increase the size of columns with a low proportion of NULL values.
To manage sparse columns, SQL Server uses a special kind of row structure that includes a column set, which is an XML representation of all the sparse columns in a table. This column set is not stored physically in the table but can be queried to retrieve data from sparse columns as if they were part of a single XML document.
To explore metadata related to sparse columns in the current database, you can use the following query, which leverages the sys.columns catalog view:
SELECT
OBJECT_NAME([object_id]) AS [TableName], [name] AS [ColumnName], [is_sparse]
FROM [sys].[columns]
WHERE [is_sparse] = 1
This query lists all sparse columns in the database, providing insights into which tables and columns are utilizing this feature.
Test it
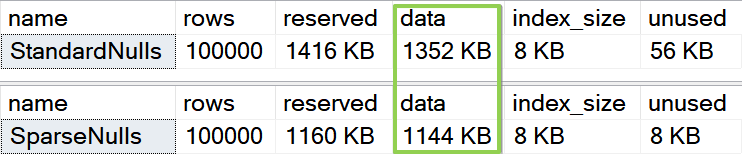
This script is designed to demonstrate the storage efficiency of sparse columns in SQL Server compared to standard nullable columns when dealing with a large volume of NULL values:
SET NOCOUNT ON
DROP TABLE IF EXISTS [dbo].[StandardNulls]
DROP TABLE IF EXISTS [dbo].[SparseNulls]
CREATE TABLE [dbo].[StandardNulls] (
[StandardNull] INT NULL
)
CREATE TABLE [dbo].[SparseNulls] (
[SparseNull] INT SPARSE
)
DECLARE @i INT = 0
WHILE @i < 100000
BEGIN
INSERT INTO [StandardNulls] ([StandardNull])
VALUES (CASE WHEN @i % 1000 = 0 THEN @i ELSE NULL END)
INSERT INTO [SparseNulls] ([SparseNull])
VALUES (CASE WHEN @i % 1000 = 0 THEN @i ELSE NULL END)
SET @i = @i + 1
END
EXEC [sp_spaceused] @objname = '[dbo].[StandardNulls]'
EXEC [sp_spaceused] @objname = '[dbo].[SparseNulls]'
GO