
Sekvence přicházejí jako novinka s SQL Serverem 2012 a přinášejí konečně ANSI standard pro generování číselných sekvencí, který v SQL Serveru dosud chyběl a ani IDENTITY či jiná různá řešení na míru ho nemohla plně nahradit. Sekvence jsou samostatné objekty, které můžeme vytvářet na úrovni databázových schémat, a nejsou přiřazeny ani tabulce ani sloupci jako tomu dosud bylo u IDENTITY. Jejich hlavním účelem je generovat číselné hodnoty ve vzestupném nebo sestupném pořadí a v intervalech definovaných při jejich vytvoření. Pro vygenerování nových hodnot jsou sekvence referencovány přímo aplikačním nebo databázovým kódem. V článku si velmi podrobně ukážeme, jak sekvence vytvářet, jaká mají nastavení, jak získávat nové hodnoty a také se z pohledu databázového vývojáře zamyslíme na tím, zda je lze považovat za plnohodnotnou náhradu IDENTITY a co by v tomto případě znamenalo nahradit v existující databázi IDENTITY sekvencemi.
1. Vytváření sekvencí
Sekvence se vytvářejí podobně jako jiné databázové objekty pomocí příkazu CREATE SEQUENCE a odstraňují se příkazem DROP SEQUENCE. Stejně je tomu i jejich změnou, která se provádí pomocí ALTER SEQUENCE.
Syntaxe příkazu CREATE SEQUENCE je následující:
CREATE SEQUENCE [schema_name . ] sequence_name
[ AS [ built_in_integer_type | user-defined_integer_type ] ]
[ START WITH <constant> ]
[ INCREMENT BY <constant> ]
[ { MINVALUE [ <constant> ] } | { NO MINVALUE } ]
[ { MAXVALUE [ <constant> ] } | { NO MAXVALUE } ]
[ CYCLE | { NO CYCLE } ]
[ { CACHE [ <constant> ] } | { NO CACHE } ]
[ ; ]
[schema_name].[sequence_name]
- Pro název sekvencí platí stejná pravidla jako pro jiné databázové objekty. Sekvence patři vždy pouze jednomu databázovému schématu a v rámci schématu musí být její název unikátní. Protože se jedná o samostatné databázové objekty, můžeme pro ně aplikovat nastavení bezpečnosti na rovni schématu na rozdíl o IDENTITY, kde žádné explicitní přiřazení práv možné nebylo.
AS [ built_in_integer_type | user-defined_integer_type ]
- Každá sekvence má svůj systémový nebo uživatelský datový typ a může se jednat pouze o některý z těchto číselných datových typů:
- tinyint – od 0 do 255
- smallint – od -32,768 do 32,767
- int – od -2,147,483,648 do 2,147,483,647
- bigint – od -9,223,372,036,854,775,808 do 9,223,372,036,854,775,807
- decimal a numeric, ale pouze s nulovým počtem desetinných míst
- uživatelské datové typy založené na výše uvedených systémových typech
- Výchozím datovým typem je bigint a je dobré na to při vytváření sekvencí pamatovat, protože pro většinu případů nebude rozsah tohoto datového typu potřeba a je vhodnější zvolit co nejmenší možný datový typ.
START WITH <constant>
- Určuje první hodnotu, kterou bude sekvence vracet. Je to nesmírně důležité nastavení, protože bez jejího použití bude první vrácenou hodnotou minimální nebo maximální hodnota použitého datového typu, a to podle toho, zda jde o sekvenci vzestupnou nebo sestupnou. Hodnota musí být samozřejmě v rozsahu zvoleného datového typu.
INCREMENT BY <constant>
- Hodnota určující velikost ikrementu nebo dekrementu při každém volání funkce NEXT VALUE FOR, která získává se sekvence další hodnotu. Hodnota nemůže být 0 a výchozí nastavení je 1. Hodnota může být pochopitelně i záporná, podobně jako u IDENTITY.
MINVALUE <constant> | NO MINVALUE
- Určuje minimální hodnotu, která bude vygenerována danou sekvencí. Pokud není určena, je minimální hodnotou vždy nejnižší hodnota použitého datového typu, případně 0 pro tinyint.
MAXVALUE <constant> | NO MAXVALUE
- Určuje horní hranici sekvence. Není-li nastavena, je horní hranicí maximální hodnota datového typu.
CYCLE | NO CYCLE
- Tato vlastnost určuje, zda se po dosažení maximální hodnoty pro vzestupné sekvence či minimální hodnoty pro sestupné sekvence má začít sekvence opět generovat od začátku. Výchozí nastavení je NO CYCLE a při dosažení hraniční maximální hodnoty je vygenerována výjimka. Nesmíme zapomenout na to, že pokud dojde k obnově cyklu, je sekvence restartována od minimální nebo maximální hodnoty, nikoliv od START WITH hodnoty.
CACHE [<constant> ] | NO CACHE
- Slouží k optimalizaci rychlosti generování dalších hodnot sekvence tím, že minimalizuje počet diskových operací. Výchozí nastavení je CACHE a velikost je nastavena na 50, i když tato hodnota není oficiálně zdokumentována a může být později změněna bez předchozího upozornění. Je tedy vždy lepší specifikovat explicitní hodnotu.
- SQL Serve si nedrží v paměti celý rozsah jednotlivých hodnot, ale pouze dvě čísla: aktuální hodnotu a počet zbývající volných hodnot v cache. Jak přesně cachování pracuje si ukážeme dále.
2. Základní sekvence
K vytvoření jednoduché sekvence nám stačí opravdu málo: spustit příkaz CREATE SEQUENCE s minimem základní nastavení:
CREATE SEQUENCE dbo.MySequence
AS INT
START WITH 1
INCREMENT BY 1 ;
GO
Naše nová sekvence je nejblíže tomu, co známe jako IDENTITY(1,1). Startovní hodnota je 1 a inkrement také 1. Pouze jsme určili datový typ INT, protože výchozí datový type BIGINT je pro většinu scénářů zbytečně velký. Naše sekvence tedy odpovídá následujícímu použití IDENTITY při definici sloupce: ID INT NOT NULL IDENTITY(1,1).
Sekvenci si můžeme prohlédnout pomocí Management Studia a upravit případně její nastavení:

Po kliknutí pravým tlačítkem -> Properties se zobrazí podrobnosti o sekvenci včetně možnosti provést její restart:

Podobně jako jiné objekty mají i sekvence své vlastní management view (DMV), kde najdeme jejich seznam a podrobnosti konfigurace:
SELECT * FROM sys.sequences
Jedinou věc, kterou nedokážeme ze sys.sequences zjistit jsou aktuální hodnoty nastavení CACHE. Ty je možné zjistit z následujících systémových tabulek, ale pouze tehdy, pokud se k instanci připojíme jako administrátoři pomocí dedikovaného připojení (DAC):
SELECT * FROM sys.sysschobjs WHERE id = OBJECT_ID('dbo.MySequence')
SELECT * FROM sys.sysobjvalues WHERE objid = OBJECT_ID('dbo.MySequence')

Jak přesně zobrazené informace číst a více o interním cache managementu sekvencí najdete zde.
3. Generování nových hodnot
Pokud již máme vytvořenou sekvenci, je čas si ukázat, jak ji budeme volat a získávat nové hodnoty pro další použití.
Existují dvě možnosti, jak můžeme generovat nového hodnoty
a) chceme získávat jedinou hodnotu (SELECT NEXT VALUE)
b) chceme získat hodnoty v určitém rozsahu (sys.sp_sequence_get_range)
SELECT NEXT VALUE FOR <sequence>
Pomocí této klauzule získáme ze sekvence novou hodnotu a to pro každé volání:
SELECT NEXT VALUE FOR dbo.MySequence AS NewSeqValue SELECT NEXT VALUE FOR dbo.MySequence AS NewSeqValue SELECT NEXT VALUE FOR dbo.MySequence AS NewSeqValue SELECT NEXT VALUE FOR dbo.MySequence AS NewSeqValue SELECT NEXT VALUE FOR dbo.MySequence AS NewSeqValue GO

Vidíme, že pro každé volání SELECT NEXT VALUE FOR jsme získali z naší sekvence další hodnotu.
sys.sp_sequence_get_range
Pomocí systémové procedury sys.sp_sequence_get_range můžeme požádat o více hodnot zároveň, což může být velmi užitečné např. pro aplikace, které zpracovávají ve více vláknech velké množství dat a provádí souběžně vkládání nových řádků do databáze. Každé vlákno si může požádat voláním procedury např. o dalších 50 hodnot sekvence a rozsah, který obdrží, se nekryje s rozsahy, které byly vygenerovány pro ostatní vlákna.
DECLARE @FirstSeqNum SQL_VARIANT, @LastSeqNum SQL_VARIANT, @CycleCount INT, @SeqIncr SQL_VARIANT, @SeqMinVal SQL_VARIANT, @SeqMaxVal sql_variant EXEC sys.sp_sequence_get_range @sequence_name = N'dbo.MySequence', @range_size = 10, @range_first_value = @FirstSeqNum OUTPUT, @range_last_value = @LastSeqNum OUTPUT, @range_cycle_count = @CycleCount OUTPUT, @sequence_increment = @SeqIncr OUTPUT, @sequence_min_value = @SeqMinVal OUTPUT, @sequence_max_value = @SeqMaxVal OUTPUT SELECT @FirstSeqNum AS FirstVal, @LastSeqNum AS LastVal, @CycleCount AS CycleCount, @SeqIncr AS SeqIncrement, @SeqMinVal AS MinSeq, @SeqMaxVal AS MaxSeq GO 3

Pomocí GO 3 jsme zavolali proceduru celkem třikrát a z výsledků vidíme, že nedostáváme seznam vygenerovaných hodnot, tedy 3 * 10 řádků, ale pouze 3 * jeden řádek, který nám říká, jaké je první a poslední hodnota našeho rozsahu (FirstVal, LastVal) a jaký je inkrement (SeqIncrement), což nám stačí k tomu, abychom si dokázali jednotlivé hodnoty dopočítat. CycleCount spolu s MinSeq a MaxSeq nám poskytují cenné informace pro případ, že získaný rozsah se vyskytuje na hranici, kdy se sekvence automaticky restartuje od začátku.
4. Cyklické sekvence
Pomocí CYCLE můžeme určit, že sekvence se po vyčerpání svého rozsahu automaticky restartuje od minimální hodnoty, kterou je buď nejmenší hodnota datového typu nebo hodnota určená pomocí MINVALUE konfigurace.
Jednoduchý příklad cyklického chování si ukážeme v následujícím skriptu:
CREATE SEQUENCE dbo.MySequence AS INT START WITH 1 INCREMENT BY 1 MINVALUE 1 MAXVALUE 3 CYCLE GO SELECT NEXT VALUE FOR dbo.[MySequence] SeqValue, name FROM [sys].[sysobjects] GO

Vytvořili jsme sekvenci dbo.MySequence a nastavili jí MINVALUE = 1 a MAXVALUE = 3 a zapnuli CYCLE. V testovacím dotazu vidíme, že sekvence se stále opakuje a může ji tak použít např. jako obdobu funkce NTILE().
Důležité je nezapomenout uvést MINVALUE nastavení, protože jinak se sekvence restartuje od minimálního hodnoty datového typu:
CREATE SEQUENCE dbo.[MySequence] AS INT START WITH 1 INCREMENT BY 1 -- MINVALUE 1 MAXVALUE 3 CYCLE GO SELECT NEXT VALUE FOR dbo.[MySequence] SeqValue, name FROM [sys].[sysobjects] GO

5. Restart sekvence
Kromě automatického restartování sekvence pomocí CYCLE můžeme sekvence restartovat od začátku pomocí následujícího příkazu:
ALTER SEQUENCE dbo.MySequence RESTART WITH 1 GO
Pokud vynecháme WITH 1, restartuje se sekvence od hodnoty určené při jejím vytvoření.
6. OVER()
Klauze OVER() nám umožňuje určit v rámci dotazu pořadí, v jakém budou hodnoty sekvence generovány vůči jednotlivým řádkům datového setu.
CREATE SEQUENCE dbo.MySequence
START WITH 1
INCREMENT BY 1
GO
SELECT NEXT VALUE FOR dbo.MySequence OVER(ORDER BY Name), name
FROM [sys].[sysobjects]
GO
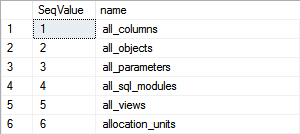
Klauzule se může zdát zbytečná, ale jen to té chvíle, než narazíme na jedno z nepříjemných omezení sekvencí: Nelze je použít v dotazu společně s TOP, ORDER a OFFSET, jak ukazuje tento příklad:
SELECT NEXT VALUE FOR dbo.[MySequence] SeqValue, name FROM [sys].[sysobjects] ORDER BY name GO
![]()
7. Transakce
Stejně jako IDENTITY i sekvence jsou generovány mimo kontext transakce a ROLLBACK vede ke ztrátě vygenerované hodnoty:
SELECT NEXT VALUE FOR dbo.MySequence SeqValue GO BEGIN TRAN SELECT NEXT VALUE FOR dbo.MySequence SeqValue ROLLBACK GO SELECT NEXT VALUE FOR dbo.MySequence SeqValue GO

8. Sekvence jako DEFAULT hodnota sloupce
Klauzuli NEXT VALUE FOR můžeme použít při vytváření tabulky jako DEFAULT hodnotu sloupce, což představuje odpověď na otázku, zda lze pomocí sekvencí nahradit klasické použití IDENTITY jako primárního klíče tabulky. Zároveň jsme schopni dosáhnout chování, které je pomocí IDENTITY nerealizovatelné:
CREATE TABLE dbo.TableA
( ID INT DEFAULT NEXT VALUE FOR dbo.MySequence PRIMARY KEY,
Value NVARCHAR(20)
);
CREATE TABLE dbo.TableB
( ID INT DEFAULT NEXT VALUE FOR dbo.MySequence PRIMARY KEY,
Value NVARCHAR(20)
);
INSERT INTO [dbo].[TableA] ( [Value] )
VALUES ('A'), ('B')
INSERT INTO [dbo].[TableB] ( [Value] )
VALUES ('C'), ('D')
INSERT INTO [dbo].[TableA] ( [Value] )
VALUES ('E'), ('F')
GO
SELECT * FROM dbo.[TableA]
SELECT * FROM dbo.[TableB]
GO
SELECT * FROM dbo.[TableA]
UNION ALL
SELECT * FROM dbo.[TableB]
ORDER BY ID
GO
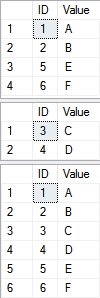
Zvýrazněné řádky ve skriptu ukazují, že jsme naši sekvenci dbo.MySequence použili jako výchozí hodnotu pro sloupec ID. Sekvenci jsme použili zároveň ve dvou tabulkách, což nám umožňuje při vkládání dat do obou tabulek mít ID hodnoty, které se nebudou překrývat. Bez sekvencí se podobné chování musí implementovat buď pomocí složité logiky nebo nebo třetí tabulky, která má sloupec IDENTITY a je zdrojem nových hodnot.
9. INSERT
Sekvence můžeme použít přímo v INSERT příkazu pro vkládání nových hodnot:
CREATE TABLE dbo.TableA ( ID INT PRIMARY KEY, Value NVARCHAR(20) ); INSERT INTO dbo.TableA ( [ID], [Value] ) VALUES (NEXT VALUE FOR dbo.MySequence, 'A'), (NEXT VALUE FOR dbo.MySequence, 'B') GO INSERT INTO dbo.TableA ( [ID], [Value] ) SELECT NEXT VALUE FOR dbo.MySequence, 'C' GO SELECT * FROM dbo.TableA GO

10. Omezení
Pro použití sekvencí existuje řada omezení, a i když lze většinu z nich obejít jiným syntaktickým zápisem nebo logikou dotazu, nejsou vždy příjemná a je třeba na ně myslet.
Sekvence nelze použít:
- v pohledech, funkcích a vypočítaných sloupcích
- jako parametr table-valued funkce
- jako argument agregačních funkcí (SUM(), …)
- ve podmínkových výrazech s použitím CASE, CHOOSE, COALESCE, IIF, ISNULL, or NULLIF
- v klauzulích FETCH, OVER, OUTPUT, ON, PIVOT, UNPIVOT, GROUP BY, HAVING, COMPUTE, COMPUTE BY, or FOR XML
- pokud je databáze v read-only režimu
- ve vnořených dotazech včetně common table expressions a odvozených tabulek
- v MERGE příkazu (kromě toho, je-li pomocí MERGE vkládáno do tabulky, kde je sekvence použita jako DEFAULT)
- jako check omezení nebo rule
- jako default v uživatelském tabulkovém typu
- v row-konstruktoru (VALUES), pokud není přímo součástí INSERTu
- ve WHERE klauzuli
- společně s TOP, OFFSET, ORDER klauzulemi
Příklady:
UNION (ALL)
SELECT NEXT VALUE FOR dbo.MySequence, * FROM sys.[columns] UNION ALL SELECT NEXT VALUE FOR dbo.MySequence, * FROM sys.[columns] GO
![]()
Error obejdeme pomocí tohoto alternativního zápisu:
SELECT NEXT VALUE FOR dbo.MySequence SEQ, * FROM ( SELECT * FROM sys.[columns] UNION ALL SELECT * FROM sys.[columns] ) a GO
ISNULL()
DECLARE @i INT SELECT ISNULL(@i,(NEXT VALUE FOR dbo.MySequence)) GO
![]()
Alternativní zápis:
DECLARE @i INT DECLARE @SEQ INT SET @SEQ = NEXT VALUE FOR dbo.[MySequence] SELECT ISNULL(@i, @SEQ) GO
11. Chyby a KB
Ze známých chyb stojí za zmínku KB3011465, kdy ve verzích SQL Server 2012 a 2014 může dojít k vygenerování duplicitních hodnot sekvencí, pokud je instance aktuálně pracuje pod nedostatkem paměti