Partitioned pohledy představují mocný nástroj a rychlou alternativu ke klasickému partitioningu tabulek. Umožňují nám rozdělit velkou tabulku do několika menších tabulek. Data jsou mezi jednotlivými tabulkami rozdělena podle rozsahu hodnot v jednom sloupci, který jsme zvolili jako klíč. Nad tímto sloupcem je v každé tabulce pomocí CHECK omezení určen rozsah hodnot, které můžou být v dané tabulce uloženy. Všechny tabulky jsou potom spojeny pomocí UNION ALL operátoru v jedno view. Pokud z tohoto view čteme data pomocí SELECT příkazu a v podmínce uvedeme sloupec, podle jehož hodnot jsme data rozdělili do jednotlivých tabulek, optimalizátor dotazů s využitím CHECK omezení správně určí, že požadovaná data se můžou nacházet pouze v určitých tabulkách a všechny ostatní tabulky při prohledávání ignoruje.
Na jednoduchém příkladě si ukážeme, jak je partitioned pohledy naimplementovat a jak vypadají exekuční plány pro různé situace.
Nejprve si připravíme tabulku se sloupcem ID a naplníme ji hodnotami 1 až 30000:
CREATE TABLE [dbo].[IdsTable] ( [Id] INT PRIMARY KEY ) GO ;WITH cte AS ( SELECT 1 ID UNION ALL SELECT ID + 1 FROM [cte] WHERE cte.ID < 30000 ) INSERT [dbo].[IdsTable] SELECT * FROM cte OPTION(MAXRECURSION 0)
Vytvoříme tři testovací tabulky objednávek pro roky 2008 až 2010. Sloupec Id definujeme jako primární klíč a pomocí CHECK omezení určíme pro každou tabulku, že může obsahovat pouze hodnoty v uvedeném rozsahu:
CREATE TABLE [dbo].[Orders2008]
( [Id] INT PRIMARY KEY
CHECK ([Id] BETWEEN 1 AND 10000),
[ProductId] INT,
[Amount] INT )
GO
CREATE TABLE [dbo].[Orders2009]
( [Id] INT PRIMARY KEY,
CHECK ([Id] BETWEEN 10001 AND 20000),
[ProductId] INT,
[Amount] INT )
GO
CREATE TABLE [dbo].[Orders2010]
( [Id] INT PRIMARY KEY,
CHECK ([Id] BETWEEN 20001 AND 30000),
[ProductId] INT,
[Amount] INT )
GO
Tabulky naplníme testovacími daty. V tomu využijeme pomocnou tabulku IdsTable vytvořenou výše. Pomocí WHERE podmínky z ní vložíme do každé ze tří tabulek objednávek pouze hodnoty příslušného rozsahu:
INSERT [dbo].[Orders2008]
SELECT [Id], [Id], ABS(CAST(CAST(NEWID() AS VARBINARY) AS INT))
FROM [dbo].[IdsTable]
WHERE [Id] BETWEEN 1 AND 10000
GO
INSERT [dbo].[Orders2009]
SELECT [Id], [Id], ABS(CAST(CAST(NEWID() AS VARBINARY) AS INT))
FROM [dbo].[IdsTable]
WHERE [Id] BETWEEN 10001 AND 20000
GO
INSERT [dbo].[Orders2010]
SELECT [Id], [Id], ABS(CAST(CAST(NEWID() AS VARBINARY) AS INT))
FROM [dbo].[IdsTable]
WHERE [Id] BETWEEN 20001 AND 30000
GO
Nyní vytvoříme vlastní view, v němž všechny tři tabulky spojíme v jeden set pomocí UNION ALL operátoru.
CREATE VIEW [dbo].[v_Orders]
WITH SCHEMABINDING
AS
SELECT [Id], [ProductId], [Amount] FROM [dbo].[Orders2008]
UNION ALL
SELECT [Id], [ProductId], [Amount] FROM [dbo].[Orders2009]
UNION ALL
SELECT [Id], [ProductId], [Amount] FROM [dbo].[Orders2010]
GO
Jak se chovají jednotlivé dotazy proti našemu pohledu si ukážeme na následujících příkladech.
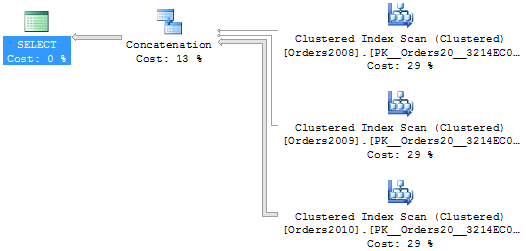
Výběr všech dat z pohledu se chová podle očekávání: SQL Server provede scan všech tří tabulek a výsledek složí do jediného setu.
SELECT * FROM [dbo].[v_Orders]
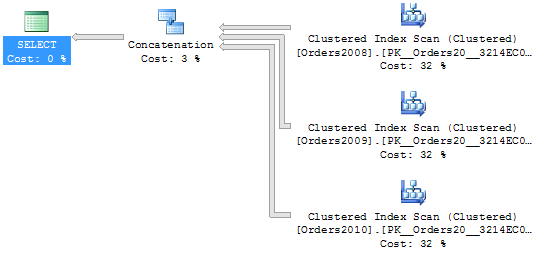
Mnohem zajímavější situace nastává, pokud použijeme filtr podle sloupce, nad kterým jsme výše definovali CHECK omezení (partitioning column):
SELECT * FROM [dbo].[v_Orders] WHERE [Id] = 5000

Z exekučního plánu vidíme, že optimalizátor hledá data pouze v tabulce objednávek za rok 2009, protože námi hledaná hodnota 5000 spadá do rozsahu omezení, které jsme pro hodnoty v této tabulce definovali (1 až 10000)). Ostatní tabulky jsou z hledání vyloučeny logickou eliminací, neboť pouhým pohledem do metadat optimalizátor dokáže zjistit, že nad nimi definovaná CHECK omezení vylučují, aby se v nich hledaná hodnota mohla vykytovat.
Obdobným způsobem se chová i hledání podle kombinace různých hodnot. Opět jsou zahrnuty pouze tabulky, kde se hledaná hodnota může vyskytovat a vyloučeny ty, kde se hodnota nikdy vyskytnout nemůže:
SELECT * FROM [dbo].[v_Orders] WHERE [Id] IN (5000, 15000)

View lze využít i pro UPDATE, ale exekuční plán nás v tomto případě může překvapit, jak ukazuje následující příklad:
UPDATE [dbo].[v_Orders]
SET [Amount] = 0
WHERE [Id] = 5000
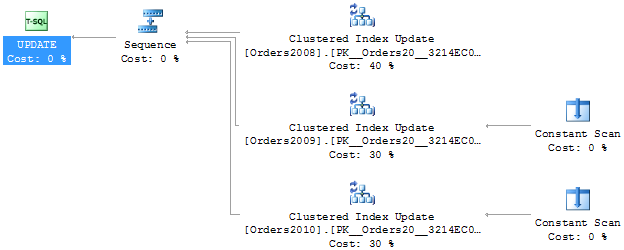
Vidíme, že v exekučním plánu jsou zahrnuty všechny tři tabulky (Clustered Index Update). Důvodem je, že optimalizátor se snaží vygenerovat takový exekuční plán, který bude možné umístit do cache a využít později. Z toho důvodu musí být plán dostatečně robustní, aby platil i pro libovolné jiné vstupní hodnoty. Výše uvedený plán je tedy univerzální v tom smyslu, že bude použitelný i tehdy, pokud podmínka WHERE Id = X bude nabývat takových hodnot, že bude vždy proveden update v jiné základní tabulce, do jejíhož rozsahu omezení vstupní hodnota spadá.
Následující příklad nám ukazuje využití stejného univerzálního plánu na jiném rozsahu hodnot:
UPDATE [dbo].[v_Orders]
SET [Amount] = 0
WHERE [Id] BETWEEN 21000 AND 29000

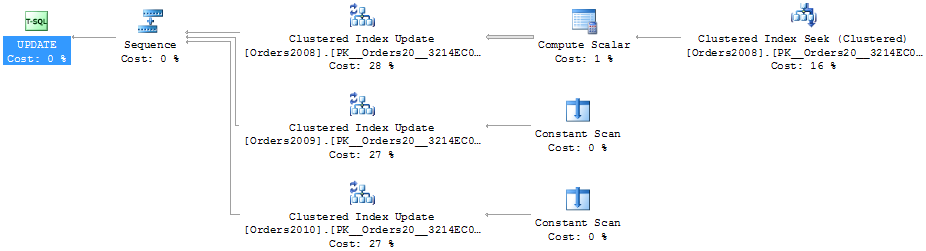
Pokud však přidáme do naší podmínky ještě sloupec Amount, vidíme, že exekuční plán již opět obsahuje část, která využívá logickou eliminaci (Clustered Index Seek):
UPDATE [dbo].[v_Orders]
SET [Amount] = 0
WHERE [Id] BETWEEN 5000 AND 6000 AND [Amount] = 50
Ve všech výše uvedených příkladech obsahovala WHERE podmínka sloupec, který jsme použili pro rozdělení dat do jednotlivých tabulek podle hodnot (CHECK omezení). Pokud však tento sloupec z WHERE podmínky vynecháme, není optimalizátor schopen využít logickou eliminaci a určit tabulky, ve kterých se hledané hodnoty nemohou vyskytovat. Nemá pak jinou možnost, než prohledat všechny tabulky a ztrácíme tím výhodu eliminace, přesně jak vidíme níže:
SELECT * FROM [dbo].[v_Orders] WHERE [Amount] = 0