
It´s legitimate expectation that a SELECT statement will return consistent results independently on number of rows returned or an internal implementation of query processing. But it is not always true. I will demonstrate it on a simple query using NEWID() function. This function should return new value on every call (row based) but it depends on which query plan operators are used during query processing and the final result can be quite different.Create dbo.Sample table with a column ID and fill 256 rows into it using the GO xxx functionality of SSMS:
CREATE TABLE dbo.SampleTable
(
Id INT IDENTITY(1,1) PRIMARY KEY
)
GO
INSERT dbo.SampleTable
DEFAULT VALUES
GO 256
Execute following queries and compare results and execution plans. The only one difference between statements is in the numer of rows to be requested by TOP operator (higlighted line).
Query 1:
SELECT
TOP 175
(SELECT Id FROM dbo.SampleTable WHERE Id = CAST(CAST(NEWID() AS VARBINARY) AS TINYINT))
FROM dbo.SampleTable
GO
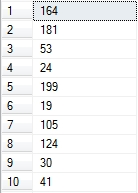
Query 2:
SELECT
TOP 176
(SELECT Id FROM dbo.SampleTable WHERE Id = CAST(CAST(NEWID() AS VARBINARY) AS TINYINT))
FROM dbo.SampleTable
GO


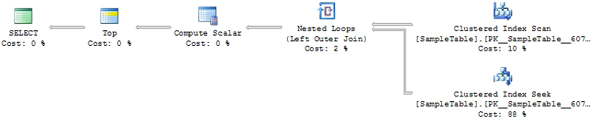
This small change in the query (in fact requesting one more row) caused new execution plan to be generated. This is common situation in the SQL Server where the optimizer is cost-based. But what is for sure not expected and predictable is that a change in execution plan means a different result set. Our sample query returns after the execution plan change the same value for all rows instead of the random value as before.
Why that happened? The difference between execution plans can explain that: There is one new operator in the second plan: Table Spool. This operator is used by the query optimizer to persist temporal set of values to the tempdb for later use and it is blocking operator by nature. This process is used whenever the optimizer knows that the density of the column is high and the intermediate result is very complex to calculate. If this is the case the optimizer makes the computation once and stores the result in the temporary space so it can search it later.
My assumption is that when the SQL Server is fetching rows from and Clustered Index Seek into Table Spool operator, it’s changing the processing mode of an index seek from a row-by-row to batch mode internally that the full set of rows received by seeking the index can be delivered to Table Spool operator. The NEWID() function is then executed only once.
The difference between the number of executions for the Clustered Index Seek can be viewed on the operator properties dialog:
Query 1: 175 executions Query 2: 1 execution


One question still remains: where the boundary value 176 is coming from? I’m not sure for now. It can be an internal optimizer threshold but this is hardly documented.
Further reading: