Common Table Expressions (CTE), dočasné pojmenované sety, představují mocný nástroj pro řešení nejrůznějších situací. Kromě jejich nejběžnějšího použití v případě, kdy potřebujeme rekurzivně procházet množinu dat, patří k jejich další zajímavé silné vlastnosti možnost spojování více CTE za sebou. V článku si ukážeme, jaký je syntaktický zápis a praktickou aplikaci. Podíváme se i na některá negativa z pohledu výkonu.
Více CTE spojíme k sobě jednoduše pomocí čárky, kterou je od sebe oddělíme dvě nebo více definic. Klauzule WITH se zapisuje pouze u první definice. Každá další definice může může přistupovat k datovému setu vytvořenému v definici předcházejí. Reference v opačném směru nejsou možné.
Celou funkcionalitu si ukážeme na následujícím jednoduchém skriptu:
WITH
CTE1 (N)
AS (
SELECT 1
UNION ALL
SELECT 2
),
CTE2 (N)
AS (
SELECT c1.N
FROM CTE1 c1
CROSS JOIN CTE1 c2
)
SELECT *
FROM CTE2
INNER JOIN CTE1 ON CTE1.N = CTE2.N
V první kroku jsme vytvořili set CTE1, který obsahuje dva řádky s hodnotami 1 a 2, spojenými pomocí UNION ALL. Definici jsme uzavřeli závorkou a čárkou, za níž jsme vytvořili definici CTE2, která již může používat předtím vytvořený set CTE1. V posledním kroku jsme v SELECT dotazu vypsali řádky ze setu CTE2, ale stejně tak dobře můžeme referencovat kterýkoliv výše definovaný set, jak v našm příkladu ukazuje INNER JOIN na CTE1.
Ačkoliv syntaktický zápis svádí k tomu, abychom předpokládali, že SQL Server uvažuje logicky a nejdříve vykoná dotaz pro CTE1, poté nad výsledkem dotaz pro CTE2, atd., ve většině případů tomu tak není a můžeme být opravdu překvapeni, co optimalizátor dotazů předvádí. Vše si ukážeme na následujících příkladech:
Nejprve si vytvoříme tabulku #TestData a naplníme ji testovacími daty:
CREATE TABLE #TestTable (ID INT NOT NULL, VALUE NVARCHAR(128)) INSERT INTO #TestTable (ID, VALUE) SELECT TOP (10000) ROW_NUMBER() OVER(ORDER BY (SELECT NULL)), v1.name FROM spt_values v1 CROSS JOIN spt_values v2 WHERE v1.name like '%PROCEDURE%' ORDER BY NEWID() GO
Nyní budeme zkoušet jednotlivé kombinace CTE a sledovat exekuční plány. Ve všech příkladech přidáváme nakonec query hint MAXDOP(1), abychom se pro zjednodušení vyhnuli paralelnímu exekučním plánu.
WITH CTE1 AS ( SELECT * FROM #TestTable WHERE VALUE LIKE '%PROCEDURE%' ), CTE2 AS ( SELECT * FROM CTE1 ), CTE3 AS ( SELECT * FROM CTE2 ) SELECT * FROM CTE1 UNION ALL SELECT * FROM CTE2 UNION ALL SELECT * FROM CTE3 OPTION(MAXDOP 1) GO
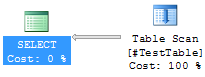
V tomto dotazu nejprve v CTE1 filtrujeme data z #TestTable a dále tento výsledek referencujeme v CTE2 a CTE2 opět v CTE3. Očekávali bychom, že SQL Server vykoná jedno čtení z tabulky #TestData v rámci CTE1, a že CTE2 a CTE3 budou pouze syntaktickým odpadem. Exekuční plán však vypadá takto:

SQL Server ve skutečnosti četl zdrojovou tabulku třikrát, a pokud se podíváme na detail jednotlivých Table Scan operátorů, vidíme, že jsou identické a všechny obsahují podmínku WHERE:
Nyní změníme náš příklad a budeme se dotazovat pouze na data z CTE3:
WITH CTE1 AS ( SELECT * FROM #TestTable WHERE VALUE LIKE '%PROCEDURE%' ), CTE2 AS ( SELECT * FROM CTE1 ), CTE3 AS ( SELECT * FROM CTE2 ) SELECT * FROM CTE3 OPTION(MAXDOP 1) GO
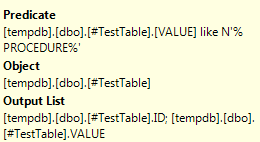
Nyní nás již optimalizátor nezklamal a vidíme, že scanoval #TestTable pouze jednou. Správně dovodil, že CTE2 a CTE3 na samotném výsledku nic nemění. Stejně chytře se optimalizátor vypořádá i s případným dalším filtrování CTE1 v CTE2 a CTE3.
Pokud ovšem například v CTE3 sáhneme po komplexnější operaci, může nás optimalizátor opět poněkud překvapit:
WITH CTE1 AS ( SELECT * FROM #TestTable WHERE VALUE LIKE '%PROCEDURE%' ), CTE2 AS ( SELECT * FROM CTE1 ), CTE3 AS ( SELECT CTE1.ID, CTE2.VALUE FROM CTE2 INNER JOIN CTE1 ON CTE1.ID = CTE2.ID ) SELECT * FROM CTE3 OPTION(MAXDOP 1) GO

Z exekučního plánu vidíme, že sice došlo k eliminaci CTE2, ale pro provedení joinu SQL Server musel provést opravdu dva scany stejné tabulky, aby byl schopen vytvořit výslednou sadu řádků.
Následující dva příklady nám ukážou, že někdy je optimalizátor neobyčejně chytrý:
WITH CTE1 AS ( SELECT * FROM #TestTable WHERE VALUE LIKE '%PROCEDURE%' ), CTE2 AS ( SELECT COUNT(*) Cnt FROM CTE1 ) SELECT * FROM CTE2 OPTION(MAXDOP 1) GO

Vidíme pouze jeden Table Scan, tedy očekávaný výsledek. Nyní udělejme drobnou úpravu a přidejme CTE3:
WITH CTE1 AS ( SELECT * FROM #TestTable WHERE VALUE LIKE '%PROCEDURE%' ), CTE2 AS ( SELECT COUNT(*) Cnt FROM CTE1 ), CTE3 AS ( SELECT COUNT(*) Cnt FROM CTE2 ) SELECT * FROM CTE3 OPTION(MAXDOP 1) GO

Výsledek je opravdu překvapivý: optimalizátor provedl logickou eliminaci, kdy správně určil, že výsledek vždy bude 1, protože CTE3 se dotazuje do CTE2, která vždy vrátí pouze jeden řádek. Není tedy vůbec třeba přistupovat ke zdrojovým datům a výsledek dotazu lze určit pouze jeho logickou analýzou.
Poslední zajímavé chování nám ukazuje následující dotaz:
WITH CTE1 AS ( SELECT * FROM #TestTable WHERE VALUE LIKE '%PROCEDURE%' ), CTE2 AS ( SELECT * FROM CTE1 WHERE VALUE LIKE '%filter%' ), CTE3 AS ( SELECT * FROM CTE2 ) SELECT * FROM CTE1 INNER JOIN CTE3 ON CTE3.ID = CTE1.ID OPTION(MAXDOP 1) GO
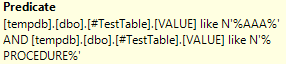
Vidíme opět dva Table Scan operátory, ale u druhého z nich nám predikát ukazuje, že SQL Server složil obě podmínky do jedné pomocí AND:
Z výše uvedeného je zřejmé, že CTE (mimo její rekurzivní funkce) je pouze syntaktickým konstruktem a při jejím spojování nelze o jednotlivých CTE uvažovat jako o dočasném datovém setu, který SQL Server vytváří někde na pozadí a následně používá pro další zpracování. Ve většině případů můžeme dosáhnout stejného nebo lepší výkonu konvenčním zápisem, např. náš poslední dotaz můžeme zapsat i takto:
SELECT ID, VALUE FROM #TestTable WHERE VALUE LIKE '%PROCEDURE%' AND VALUE LIKE '%filter%' GO
Odměnou je nám jednoduchý exekuční plán přesně dle očekávání: